Suppose that a patient is to be screened for a certain disease or medical condition. There are two important questions at the outset. How accurate is the screen or test? For example, at the outset, what is the probability of the test giving the correct result? The second question: once the patient obtains the test result (positive or negative), how reliable is the result? These two questions seem one and the same. Confusing these two questions as the same is a common misconception. Sometimes even medical doctors can get it wrong. This post demonstrates how to sort out these questions using Bayes’ formula or Bayes’ theorem.
Example
Before a patient is screened, a relevant question is on the accuracy of the test. Once the test result comes back, an important question is on whether positive result means having the disease and negative result means healthy. Here’s the two questions that are of interest:
- What is the probability of the test giving a correct result, positive for someone with the disease and negative for someone who is healthy?
- Once the test result is back, what is the probability that the test result is correct? More specifically, if a patient is tested positive, what is the probability that the patient has the disease? If a patient is tested negative, what is the probability that the patient is healthy?
Both questions involve conditional probabilities. In fact, the conditional probabilities in the second question are the reverse of the ones in the first question. To illustrate, we use the following example.
Example. Suppose that the prevalence of a disease is 1%. This disease has no particular symptoms but can be screened by a medical test that is 90% accurate. This means that the test result is positive about 90% of the times when it is applied on patients who have the disease and that the test result is negative about 90% of the time when it is applied on patients who do not have the disease. Suppose that you take the test and the test shows a positive result. Then the burning question is: how likely is it that you have the disease? Similarly, how likely is it that the patient is healthy if the test result is negative?
The accuracy of the test is 90% (0.90 as a probability). Since there is a 90% chance the test works correctly, if the patient has the disease, there is a 90% chance that the test will come back positive and if the patient is healthy, there is a 90% chance the test will come back negative. If a patient tested positive, wouldn’t it mean that there is a 90% chance that the patient has the disease?
Note that the given number of 90% is for the conditional events: “if disease, then positive” and “if healthy, then negative.” The example asks for the probabilities for the reversed events – “if positive, then disease”and “if negative, then healthy.” It is a common misconception that the two probabilities are the same.
Tree Diagrams
Let’s use a tree diagrams to look at this problem in a systematic way. First let 



Then ![P[+ \lvert S]=0.90](https://s0.wp.com/latex.php?latex=P%5B%2B+%5Clvert+S%5D%3D0.90&bg=ffffff&fg=333333&s=0&c=20201002)
![P[- \lvert H]=0.90](https://s0.wp.com/latex.php?latex=P%5B-+%5Clvert+H%5D%3D0.90&bg=ffffff&fg=333333&s=0&c=20201002)
![P[S \lvert +]](https://s0.wp.com/latex.php?latex=P%5BS+%5Clvert+%2B%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![P[H \lvert -]](https://s0.wp.com/latex.php?latex=P%5BH+%5Clvert+-%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![P[+ \lvert S]](https://s0.wp.com/latex.php?latex=P%5B%2B+%5Clvert+S%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![P[- \lvert H]](https://s0.wp.com/latex.php?latex=P%5B-+%5Clvert+H%5D&bg=ffffff&fg=333333&s=0&c=20201002)

Figure 1 – Structure of Tree Diagram
At the root of the tree diagram is a randomly chosen patient being tested. The first level of the tree shows the disease status (H or S). The events at the first level are unconditional events. The next level of the tree shows the test status (+ or -). Note that the test status is a conditional event. For example, the + that follows H is the event 

Figure 2 – Tree Diagram with Probabilities
The probabilities at the first level of the tree are the unconditional probabilities ![P[H]](https://s0.wp.com/latex.php?latex=P%5BH%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![P[S]](https://s0.wp.com/latex.php?latex=P%5BS%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![P[H] \times P[+ \lvert H]](https://s0.wp.com/latex.php?latex=P%5BH%5D+%5Ctimes+P%5B%2B+%5Clvert+H%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![P[H \text{ and } +]](https://s0.wp.com/latex.php?latex=P%5BH+%5Ctext%7B+and+%7D+%2B%5D&bg=ffffff&fg=333333&s=0&c=20201002)

Figure 3 – Tree Diagram with Numerical Probabilities
Figure 3 shows four paths – “H and +”, “H and -“, “S and +” and “S and -“. With 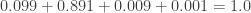
![P[+]=0.099+0.009=0.108](https://s0.wp.com/latex.php?latex=P%5B%2B%5D%3D0.099%2B0.009%3D0.108&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle P[S \lvert +]=\frac{0.009}{0.009+0.099}=\frac{0.009}{0.108}=0.0833=8.33 \%](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+P%5BS+%5Clvert+%2B%5D%3D%5Cfrac%7B0.009%7D%7B0.009%2B0.099%7D%3D%5Cfrac%7B0.009%7D%7B0.108%7D%3D0.0833%3D8.33+%5C%25&bg=ffffff&fg=333333&s=0&c=20201002)
In this example, the forward conditional probability is ![P[+ \lvert S]=0.9](https://s0.wp.com/latex.php?latex=P%5B%2B+%5Clvert+S%5D%3D0.9&bg=ffffff&fg=333333&s=0&c=20201002)
![P[S \lvert +]=0.0833](https://s0.wp.com/latex.php?latex=P%5BS+%5Clvert+%2B%5D%3D0.0833&bg=ffffff&fg=333333&s=0&c=20201002)
According to Figure 3, ![P[-]=0.891+0.001=0.892](https://s0.wp.com/latex.php?latex=P%5B-%5D%3D0.891%2B0.001%3D0.892&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle P[H \lvert -]=\frac{0.891}{0.891+0.001}=\frac{0.891}{0.892}=0.9989=99.89 \%](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+P%5BH+%5Clvert+-%5D%3D%5Cfrac%7B0.891%7D%7B0.891%2B0.001%7D%3D%5Cfrac%7B0.891%7D%7B0.892%7D%3D0.9989%3D99.89+%5C%25&bg=ffffff&fg=333333&s=0&c=20201002)
Most of the negative results are actual negatives. So there are very few false negatives. Once gain, the forward conditional probability
Bayes’ Formula
The result
Though not mentioned by name, the above tree diagrams use the idea of Bayes’ formula or Bayes’ rule to reverse the forward conditional probabilities to obtain the backward conditional probabilities. This process has been discribed in this previous post.
The above tree diagrams describe a two-stage experiment. Pick a patient at random and the patient is either healthy or sick (the first stage in the experiment). Then the patient is tested and the result is either positive or negative (the second stage). A forward conditional probability is a probability of the status in the second stage given the status in the first stage of the experiment. The backward conditional probability is the probability of the status in the first stage given the status in the second stage. A backward conditional probability is also called a Bayes probability.
Let’s examine the backward conditional probability
![\displaystyle P[S \lvert +]=\frac{P[S \text{ and } +]}{P[+]}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+P%5BS+%5Clvert+%2B%5D%3D%5Cfrac%7BP%5BS+%5Ctext%7B+and+%7D+%2B%5D%7D%7BP%5B%2B%5D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
Note that two of the paths in Figure 3 have positive test results (marked with red). Thus ![P[+]](https://s0.wp.com/latex.php?latex=P%5B%2B%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![P[+]=P[H] \times P(+ \lvert H)+P[S] \times P(+ \lvert S)](https://s0.wp.com/latex.php?latex=P%5B%2B%5D%3DP%5BH%5D+%5Ctimes+P%28%2B+%5Clvert+H%29%2BP%5BS%5D+%5Ctimes+P%28%2B+%5Clvert+S%29&bg=ffffff&fg=333333&s=0&c=20201002)
![P[S \text{ and } +]=P[S] \times P[+ \lvert S]](https://s0.wp.com/latex.php?latex=P%5BS+%5Ctext%7B+and+%7D+%2B%5D%3DP%5BS%5D+%5Ctimes+P%5B%2B+%5Clvert+S%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle P[S \lvert +]=\frac{P[S] \times P(+ \lvert S)}{P[H] \times P(+ \lvert H)+P[S] \times P(+ \lvert S)}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+P%5BS+%5Clvert+%2B%5D%3D%5Cfrac%7BP%5BS%5D+%5Ctimes+P%28%2B+%5Clvert+S%29%7D%7BP%5BH%5D+%5Ctimes+P%28%2B+%5Clvert+H%29%2BP%5BS%5D+%5Ctimes+P%28%2B+%5Clvert+S%29%7D&bg=ffffff&fg=333333&s=0&c=20201002)
The above is the Bayes’ formula in the specific context of a medical diagnostic test. Though a famous formula, there is no need to memorize it. If using the tree diagram approach, look for the two paths for the positive test results. The ratio of the path for “sick” patients to the sum of the two paths would be the backward conditional probability
Regardless of using tree diagrams, the Bayesian idea is that a positive test result is explained by two causes. One is that the patient is healthy. Then the contribution to a positive result is ![P[H \text{ and } +]=P[H] \times P[+ \lvert H]](https://s0.wp.com/latex.php?latex=P%5BH+%5Ctext%7B+and+%7D+%2B%5D%3DP%5BH%5D+%5Ctimes+P%5B%2B+%5Clvert+H%5D&bg=ffffff&fg=333333&s=0&c=20201002)
Further Discussion of the Example
The calculation in Figure 3 is based on the prevalence of the disease of 1%, i.e. ![P[S]=0.01](https://s0.wp.com/latex.php?latex=P%5BS%5D%3D0.01&bg=ffffff&fg=333333&s=0&c=20201002)
Let’s try some extreme examples. Suppose that we are to test for a disease that nobody has (think testing for ovarian cancer among men or prostate cancer among women). Then we would have no confidence on a positive test result. In such a scenario, all positives would be healthy people. Any healthy patient that receives a positive result would be called a false positive. Thus in the extreme scenario of a disease with 0% prevalence among the patients being tested, we do not have any confidence on a positive result being correct.
On the other hand, suppose we are to test for a disease that everybody has. Then it would then be clear that a positive result would always be a correct result. In such a scenario, all positives would be sick patients. Any sick patient that receives a positive test result is called a true positive. Thus in the extreme scenario of a disease with 100% prevalence, we would have great confidence on a positive result being correct.
Thus prevalence of a disease has to be taken into account in the calculation for the backward conditional probability

Figure 4 – Tree Diagram with 10,000 Patients
Out of 10,000 patients being tested, 100 of them are expected to have the disease in question and 9,900 of them are healthy. With the test being 90% accurate, about 90 of the 100 sick patients would show positive results (these are the true positives). On the other hand, there would be about 990 false positives (10% of the 9,900 healthy patients). There are 990 + 90 = 1,080 positives in total and only 90 of them are true positives. Thus
What if the disease in question has a prevalence of 8.33%? What would be the backward conditional probability
![\displaystyle \begin{aligned} P[S \lvert +]&=\frac{P[S] \times P(+ \lvert S)}{P[H] \times P(+ \lvert H)+P[S] \times P(+ \lvert S)} \\&=\frac{0.0833 \times 0.9}{0.9167 \times 0.1+0.0833 \times 0.9} =0.44989 \approx 45 \% \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+P%5BS+%5Clvert+%2B%5D%26%3D%5Cfrac%7BP%5BS%5D+%5Ctimes+P%28%2B+%5Clvert+S%29%7D%7BP%5BH%5D+%5Ctimes+P%28%2B+%5Clvert+H%29%2BP%5BS%5D+%5Ctimes+P%28%2B+%5Clvert+S%29%7D+%5C%5C%26%3D%5Cfrac%7B0.0833+%5Ctimes+0.9%7D%7B0.9167+%5Ctimes+0.1%2B0.0833+%5Ctimes+0.9%7D+%3D0.44989+%5Capprox+45+%5C%25++%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)
With ![P[S \lvert +]=0.45](https://s0.wp.com/latex.php?latex=P%5BS+%5Clvert+%2B%5D%3D0.45&bg=ffffff&fg=333333&s=0&c=20201002)
![P[S]=0.0833](https://s0.wp.com/latex.php?latex=P%5BS%5D%3D0.0833&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle \begin{aligned} P[S \lvert +]&=\frac{P[S] \times P(+ \lvert S)}{P[H] \times P(+ \lvert H)+P[S] \times P(+ \lvert S)} \\&=\frac{0.45 \times 0.9}{0.55 \times 0.1+0.45 \times 0.9} =0.88043 \approx 88 \% \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+P%5BS+%5Clvert+%2B%5D%26%3D%5Cfrac%7BP%5BS%5D+%5Ctimes+P%28%2B+%5Clvert+S%29%7D%7BP%5BH%5D+%5Ctimes+P%28%2B+%5Clvert+H%29%2BP%5BS%5D+%5Ctimes+P%28%2B+%5Clvert+S%29%7D+%5C%5C%26%3D%5Cfrac%7B0.45+%5Ctimes+0.9%7D%7B0.55+%5Ctimes+0.1%2B0.45+%5Ctimes+0.9%7D+%3D0.88043+%5Capprox+88+%5C%25++%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)
With the prevalence being 45%, the probability of a positive being a true positive is 88%. The calculation shows that when the disease or condition is widespread, a positive result should be taken seriously.
One thing is clear. The backward conditional probability
Bayesian Updating Based on New Information
The calculation shown above using the Bayes’ formula can be interpreted as updating probabilities in light of new information, in this case, updating risk of having a disease based on test results. With the hypothetical disease having a prevalence of 1% being discussed above, the initial risk is 1%. With one round of testing using a test with 90% accuracy, the risk is updated to 8.33%. For the patients who test positive in the first round of testing, the risk is raised to 8.33%. They can then go through a second round of testing using another test (but also with 90% accuracy). For the patients who test positive in the second round, the risk is updated to 45%. For the positives in the third round of testing, the risk is updated to 88%. The successive Bayesian calculation can be regarded as sequential updating of probabilities. Such updating would not be easy without the idea of the Bayes’ rule or formula.
Sensitivity and Specificity
The sensitivity of a medical diagnostic test is the ability to give correct results for the people who have the disease. Putting it in another way, the sensitivity is the true positive rate, which would be the percentage of sick people who are correctly identified as having the disease. In other words, the sensitivity of a test is the probability of a correct test result for the people with the disease. In our discussion, the sensitivity is the conditional forward probability
The specificity of a medical diagnostic test is the ability to give correct results for the people who do not have the disease. The specificity is then the true negative rate, which would be the percentage of healthy people who are correctly identified as not having the disease. In other words, the specificity of a test is the probability of a correct test result for healthy people. In our discussion, the specificity is the conditional forward probability
With the sensitivity being the conditional forward probability
In the example discussed here, both the sensitivity and specificity are 90%. This scenario is certainly ideal. In medical testing, the accuracy of a test for a disease may not be the same for the sick people and for the healthy people. For a simple example, let’s say we use chest pain as a criterion to diagnose a heart attack. This would be a very sensitive test since almost all people experiencing heart attack will have chest pain. However, it would be a test with low specificity since there would be plenty of other reasons for the symptom of chest pain.
Thus it is possible that a test may be very accurate for the people who have the disease but nonetheless identify many healthy people as positive. In other words, some tests have high sensitivity but have much lower specificity.
In medical testing, the overriding concern is to use a test with high sensitivity. The reason is that a high true positive rate leads to a low false negative rate. So the goal is to have as few false negative cases as possible in order to correctly diagnose as many sick people as possible. The trade off is that there may be a higher number of false positives, which is considered to be less alarming than missing people who have the disease. The usual practice is that a first test for a disease has high sensitivity but lower specificity. To weed out the false positives, the positives in the first round of testing will use another test that has a higher specificity.