Suppose that a patient is to be screened for a certain disease or medical condition. There are two important questions at the outset. How accurate is the screen or test? For example, at the outset, what is the probability of the test giving the correct result? The second question: once the patient obtains the test result (positive or negative), how reliable is the result? These two questions seem one and the same. Confusing these two questions as the same is a common misconception. Sometimes even medical doctors can get it wrong. This post demonstrates how to sort out these questions using Bayes’ formula or Bayes’ theorem.
Example
Before a patient is screened, a relevant question is on the accuracy of the test. Once the test result comes back, an important question is on whether positive result means having the disease and negative result means healthy. Here’s the two questions that are of interest:
- What is the probability of the test giving a correct result, positive for someone with the disease and negative for someone who is healthy?
- Once the test result is back, what is the probability that the test result is correct? More specifically, if a patient is tested positive, what is the probability that the patient has the disease? If a patient is tested negative, what is the probability that the patient is healthy?
Both questions involve conditional probabilities. In fact, the conditional probabilities in the second question are the reverse of the ones in the first question. To illustrate, we use the following example.
Example. Suppose that the prevalence of a disease is 1%. This disease has no particular symptoms but can be screened by a medical test that is 90% accurate. This means that the test result is positive about 90% of the times when it is applied on patients who have the disease and that the test result is negative about 90% of the time when it is applied on patients who do not have the disease. Suppose that you take the test and the test shows a positive result. Then the burning question is: how likely is it that you have the disease? Similarly, how likely is it that the patient is healthy if the test result is negative?
The accuracy of the test is 90% (0.90 as a probability). Since there is a 90% chance the test works correctly, if the patient has the disease, there is a 90% chance that the test will come back positive and if the patient is healthy, there is a 90% chance the test will come back negative. If a patient tested positive, wouldn’t it mean that there is a 90% chance that the patient has the disease?
Note that the given number of 90% is for the conditional events: “if disease, then positive” and “if healthy, then negative.” The example asks for the probabilities for the reversed events – “if positive, then disease”and “if negative, then healthy.” It is a common misconception that the two probabilities are the same.
Tree Diagrams
Let’s use a tree diagrams to look at this problem in a systematic way. First let  be the event that the patient being tested is healthy (does not have the disease in question) and let
be the event that the patient being tested is healthy (does not have the disease in question) and let  be the event that the patient being tested is sick (has the disease in question). Let
be the event that the patient being tested is sick (has the disease in question). Let  denote the event that the test result is positive if the patient has the disease. Let
denote the event that the test result is positive if the patient has the disease. Let  denote the event that the test result is negative if the patient is healthy.
denote the event that the test result is negative if the patient is healthy.
Then ![P[+ \lvert S]=0.90](https://s0.wp.com/latex.php?latex=P%5B%2B+%5Clvert+S%5D%3D0.90&bg=ffffff&fg=333333&s=0&c=20201002) and
and ![P[- \lvert H]=0.90](https://s0.wp.com/latex.php?latex=P%5B-+%5Clvert+H%5D%3D0.90&bg=ffffff&fg=333333&s=0&c=20201002) . These two conditional probabilities are based on the accuracy of the test. These probabilities are in a sense chronological – the patient either is healthy or sick and then is being tested. The example asks for the conditional probabilities
. These two conditional probabilities are based on the accuracy of the test. These probabilities are in a sense chronological – the patient either is healthy or sick and then is being tested. The example asks for the conditional probabilities ![P[S \lvert +]](https://s0.wp.com/latex.php?latex=P%5BS+%5Clvert+%2B%5D&bg=ffffff&fg=333333&s=0&c=20201002) and
and ![P[H \lvert -]](https://s0.wp.com/latex.php?latex=P%5BH+%5Clvert+-%5D&bg=ffffff&fg=333333&s=0&c=20201002) , which are backward from the given conditional probabilities, and are also backward in a chronological sense. We call
, which are backward from the given conditional probabilities, and are also backward in a chronological sense. We call ![P[+ \lvert S]](https://s0.wp.com/latex.php?latex=P%5B%2B+%5Clvert+S%5D&bg=ffffff&fg=333333&s=0&c=20201002) and
and ![P[- \lvert H]](https://s0.wp.com/latex.php?latex=P%5B-+%5Clvert+H%5D&bg=ffffff&fg=333333&s=0&c=20201002) forward conditional probabilities. We call and backward conditional probabilities. Bayes’ formula is a good way to compute the backward conditional probabilities. The following diagram shows the structure of the tree diagram.
forward conditional probabilities. We call and backward conditional probabilities. Bayes’ formula is a good way to compute the backward conditional probabilities. The following diagram shows the structure of the tree diagram.
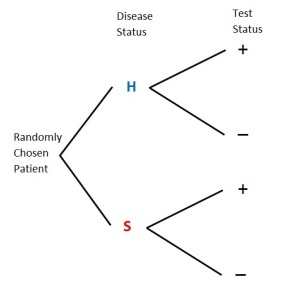
Figure 1 – Structure of Tree Diagram
At the root of the tree diagram is a randomly chosen patient being tested. The first level of the tree shows the disease status (H or S). The events at the first level are unconditional events. The next level of the tree shows the test status (+ or -). Note that the test status is a conditional event. For example, the + that follows H is the event  and the – that follows H is the event . The next diagram shows the probabilities that are in the tree diagram.
and the – that follows H is the event . The next diagram shows the probabilities that are in the tree diagram.
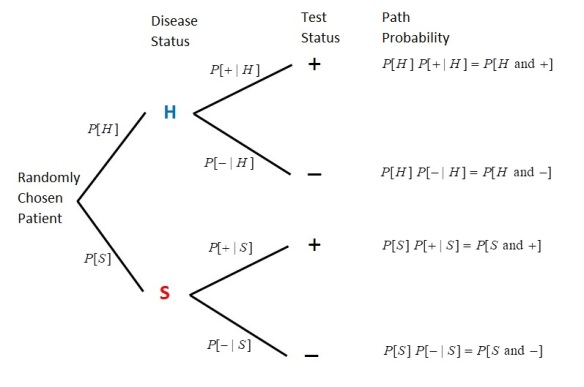
Figure 2 – Tree Diagram with Probabilities
The probabilities at the first level of the tree are the unconditional probabilities ![P[H]](https://s0.wp.com/latex.php?latex=P%5BH%5D&bg=ffffff&fg=333333&s=0&c=20201002) and
and ![P[S]](https://s0.wp.com/latex.php?latex=P%5BS%5D&bg=ffffff&fg=333333&s=0&c=20201002) , where is the prevalence of the disease. The probabilities at the second level of the tree are conditional probabilities (the probabilities of the test status conditional on the disease status). A path probability is the product of the probabilities in a given path. For example, the path probability of the first path is
, where is the prevalence of the disease. The probabilities at the second level of the tree are conditional probabilities (the probabilities of the test status conditional on the disease status). A path probability is the product of the probabilities in a given path. For example, the path probability of the first path is ![P[H] \times P[+ \lvert H]](https://s0.wp.com/latex.php?latex=P%5BH%5D+%5Ctimes+P%5B%2B+%5Clvert+H%5D&bg=ffffff&fg=333333&s=0&c=20201002) , which equals
, which equals ![P[H \text{ and } +]](https://s0.wp.com/latex.php?latex=P%5BH+%5Ctext%7B+and+%7D+%2B%5D&bg=ffffff&fg=333333&s=0&c=20201002) . Thus a path probability is the probability of the event “disease status and test status.” The next diagram displays the numerical probabilities.
. Thus a path probability is the probability of the event “disease status and test status.” The next diagram displays the numerical probabilities.
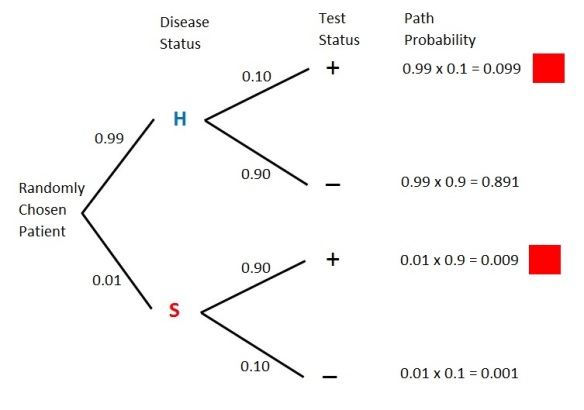
Figure 3 – Tree Diagram with Numerical Probabilities
Figure 3 shows four paths – “H and +”, “H and -“, “S and +” and “S and -“. With 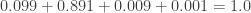 , the sum of the four path probabilities is 1.0. These probabilities show the long run proportions of the patients that fall into these 4 categories. The path that is most likely is the path “H and -“, which happens 89.1% of the time. This makes sense since the disease in question is one that has low prevalence (only 1%). The two paths marked in red are the paths for positive test status. Thus
, the sum of the four path probabilities is 1.0. These probabilities show the long run proportions of the patients that fall into these 4 categories. The path that is most likely is the path “H and -“, which happens 89.1% of the time. This makes sense since the disease in question is one that has low prevalence (only 1%). The two paths marked in red are the paths for positive test status. Thus ![P[+]=0.099+0.009=0.108](https://s0.wp.com/latex.php?latex=P%5B%2B%5D%3D0.099%2B0.009%3D0.108&bg=ffffff&fg=333333&s=0&c=20201002) . Thus about 10.8% of the patients being tested will show a positive result. Of these, how many of them actually have the disease?
. Thus about 10.8% of the patients being tested will show a positive result. Of these, how many of them actually have the disease?
![\displaystyle P[S \lvert +]=\frac{0.009}{0.009+0.099}=\frac{0.009}{0.108}=0.0833=8.33 \%](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+P%5BS+%5Clvert+%2B%5D%3D%5Cfrac%7B0.009%7D%7B0.009%2B0.099%7D%3D%5Cfrac%7B0.009%7D%7B0.108%7D%3D0.0833%3D8.33+%5C%25&bg=ffffff&fg=333333&s=0&c=20201002)
In this example, the forward conditional probability is ![P[+ \lvert S]=0.9](https://s0.wp.com/latex.php?latex=P%5B%2B+%5Clvert+S%5D%3D0.9&bg=ffffff&fg=333333&s=0&c=20201002) . As the tree diagrams have shown, the backward conditional probability is
. As the tree diagrams have shown, the backward conditional probability is ![P[S \lvert +]=0.0833](https://s0.wp.com/latex.php?latex=P%5BS+%5Clvert+%2B%5D%3D0.0833&bg=ffffff&fg=333333&s=0&c=20201002) . Of all the positive cases, only 8.33% of them are actually sick. The other 91.67% are false positives. Confusing the forward conditional probability as the backward conditional probability is a common mistake. In fact, sometimes medical doctors got it wrong according to a 1978 article in New England Journal of Medicine. Though we are using tree diagrams to present the solution, the answer of 8.33% is obtained by the Bayes’ formula. We will discuss this in more details below.
. Of all the positive cases, only 8.33% of them are actually sick. The other 91.67% are false positives. Confusing the forward conditional probability as the backward conditional probability is a common mistake. In fact, sometimes medical doctors got it wrong according to a 1978 article in New England Journal of Medicine. Though we are using tree diagrams to present the solution, the answer of 8.33% is obtained by the Bayes’ formula. We will discuss this in more details below.
According to Figure 3, ![P[-]=0.891+0.001=0.892](https://s0.wp.com/latex.php?latex=P%5B-%5D%3D0.891%2B0.001%3D0.892&bg=ffffff&fg=333333&s=0&c=20201002) . Of these patients, how many of them are actually healthy?
. Of these patients, how many of them are actually healthy?
Most of the negative results are actual negatives. So there are very few false negatives. Once gain, the forward conditional probability is not to be confused with the backward conditional probability .
Bayes’ Formula
The result seems startling. Thus if a patient tested positive, there is only a slightly more than 8% chance that the patient actually has the disease! It seems that the test is not very accurate and seems to be not reliable. Before commenting on this result, let’s summarize the calculation implicit in the tree diagrams.
Though not mentioned by name, the above tree diagrams use the idea of Bayes’ formula or Bayes’ rule to reverse the forward conditional probabilities to obtain the backward conditional probabilities. This process has been discribed in this previous post.
The above tree diagrams describe a two-stage experiment. Pick a patient at random and the patient is either healthy or sick (the first stage in the experiment). Then the patient is tested and the result is either positive or negative (the second stage). A forward conditional probability is a probability of the status in the second stage given the status in the first stage of the experiment. The backward conditional probability is the probability of the status in the first stage given the status in the second stage. A backward conditional probability is also called a Bayes probability.
Let’s examine the backward conditional probability . The following is the definition of the conditional probability .
Note that two of the paths in Figure 3 have positive test results (marked with red). Thus ![P[+]](https://s0.wp.com/latex.php?latex=P%5B%2B%5D&bg=ffffff&fg=333333&s=0&c=20201002) is the sum of two quantities with
is the sum of two quantities with ![P[+]=P[H] \times P(+ \lvert H)+P[S] \times P(+ \lvert S)](https://s0.wp.com/latex.php?latex=P%5B%2B%5D%3DP%5BH%5D+%5Ctimes+P%28%2B+%5Clvert+H%29%2BP%5BS%5D+%5Ctimes+P%28%2B+%5Clvert+S%29&bg=ffffff&fg=333333&s=0&c=20201002) . One of the quantities is for the case of the patient being healthy and the other is for the case of the patient being sick. With
. One of the quantities is for the case of the patient being healthy and the other is for the case of the patient being sick. With ![P[S \text{ and } +]=P[S] \times P[+ \lvert S]](https://s0.wp.com/latex.php?latex=P%5BS+%5Ctext%7B+and+%7D+%2B%5D%3DP%5BS%5D+%5Ctimes+P%5B%2B+%5Clvert+S%5D&bg=ffffff&fg=333333&s=0&c=20201002) , and plugging in ,
, and plugging in ,
The above is the Bayes’ formula in the specific context of a medical diagnostic test. Though a famous formula, there is no need to memorize it. If using the tree diagram approach, look for the two paths for the positive test results. The ratio of the path for “sick” patients to the sum of the two paths would be the backward conditional probability .
Regardless of using tree diagrams, the Bayesian idea is that a positive test result is explained by two causes. One is that the patient is healthy. Then the contribution to a positive result is ![P[H \text{ and } +]=P[H] \times P[+ \lvert H]](https://s0.wp.com/latex.php?latex=P%5BH+%5Ctext%7B+and+%7D+%2B%5D%3DP%5BH%5D+%5Ctimes+P%5B%2B+%5Clvert+H%5D&bg=ffffff&fg=333333&s=0&c=20201002) . The other cause of a positive result is that the patient is sick. Then the contribution to a positive result is . The ratio of the “sick” cause to the sum total of the two causes is the backward conditional probability . However, a tree diagram is clearly a very handy device to clarify the Bayesian calculation.
. The other cause of a positive result is that the patient is sick. Then the contribution to a positive result is . The ratio of the “sick” cause to the sum total of the two causes is the backward conditional probability . However, a tree diagram is clearly a very handy device to clarify the Bayesian calculation.
Further Discussion of the Example
The calculation in Figure 3 is based on the prevalence of the disease of 1%, i.e. ![P[S]=0.01](https://s0.wp.com/latex.php?latex=P%5BS%5D%3D0.01&bg=ffffff&fg=333333&s=0&c=20201002) . The hypothetical disease in the example affects one person in 100. With being relatively small (just 8.33%), we cannot place much confidence on a positive result. One important point to understand is that the confidence on a positive result is determined by the prevalence of the disease in addition to the accuracy of the test. Thus the less common the disease, the less confidence we can place on a positive result. On the other hand, the more common the disease, the more confidence we can place on a positive result.
. The hypothetical disease in the example affects one person in 100. With being relatively small (just 8.33%), we cannot place much confidence on a positive result. One important point to understand is that the confidence on a positive result is determined by the prevalence of the disease in addition to the accuracy of the test. Thus the less common the disease, the less confidence we can place on a positive result. On the other hand, the more common the disease, the more confidence we can place on a positive result.
Let’s try some extreme examples. Suppose that we are to test for a disease that nobody has (think testing for ovarian cancer among men or prostate cancer among women). Then we would have no confidence on a positive test result. In such a scenario, all positives would be healthy people. Any healthy patient that receives a positive result would be called a false positive. Thus in the extreme scenario of a disease with 0% prevalence among the patients being tested, we do not have any confidence on a positive result being correct.
On the other hand, suppose we are to test for a disease that everybody has. Then it would then be clear that a positive result would always be a correct result. In such a scenario, all positives would be sick patients. Any sick patient that receives a positive test result is called a true positive. Thus in the extreme scenario of a disease with 100% prevalence, we would have great confidence on a positive result being correct.
Thus prevalence of a disease has to be taken into account in the calculation for the backward conditional probability . For the hypothetical disease discussed here, let’s look at the long run results of applying the test to 10,000 patients. The next tree diagram shows the results.
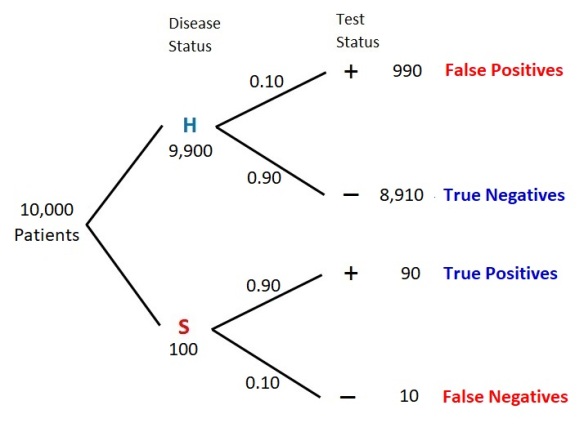
Figure 4 – Tree Diagram with 10,000 Patients
Out of 10,000 patients being tested, 100 of them are expected to have the disease in question and 9,900 of them are healthy. With the test being 90% accurate, about 90 of the 100 sick patients would show positive results (these are the true positives). On the other hand, there would be about 990 false positives (10% of the 9,900 healthy patients). There are 990 + 90 = 1,080 positives in total and only 90 of them are true positives. Thus is 90/1080 = 8.33%.
What if the disease in question has a prevalence of 8.33%? What would be the backward conditional probability assuming that the test is still 90% accurate?
With ![P[S \lvert +]=0.45](https://s0.wp.com/latex.php?latex=P%5BS+%5Clvert+%2B%5D%3D0.45&bg=ffffff&fg=333333&s=0&c=20201002) , there is a great deal more confidence on a positive result. With the test accuracy being the same (90%), the greater confidence is due to the greater prevalence of the disease. With
, there is a great deal more confidence on a positive result. With the test accuracy being the same (90%), the greater confidence is due to the greater prevalence of the disease. With ![P[S]=0.0833](https://s0.wp.com/latex.php?latex=P%5BS%5D%3D0.0833&bg=ffffff&fg=333333&s=0&c=20201002) being greater than 0.01, a greater portion of the positives would be true positives. The higher the prevalence of the disease, the greater the probability . Just to further illustrate this point, suppose the test for a disease has a 90% accuracy rate and the prevalence for the disease is 45%. The following calculation gives .
being greater than 0.01, a greater portion of the positives would be true positives. The higher the prevalence of the disease, the greater the probability . Just to further illustrate this point, suppose the test for a disease has a 90% accuracy rate and the prevalence for the disease is 45%. The following calculation gives .
With the prevalence being 45%, the probability of a positive being a true positive is 88%. The calculation shows that when the disease or condition is widespread, a positive result should be taken seriously.
One thing is clear. The backward conditional probability is not to be confused with the forward conditional probability . Furthermore, it will not be easy to invert the forward conditional probability without using Bayes’ formula (either using the formula explicitly or using a tree diagram).
Bayesian Updating Based on New Information
The calculation shown above using the Bayes’ formula can be interpreted as updating probabilities in light of new information, in this case, updating risk of having a disease based on test results. With the hypothetical disease having a prevalence of 1% being discussed above, the initial risk is 1%. With one round of testing using a test with 90% accuracy, the risk is updated to 8.33%. For the patients who test positive in the first round of testing, the risk is raised to 8.33%. They can then go through a second round of testing using another test (but also with 90% accuracy). For the patients who test positive in the second round, the risk is updated to 45%. For the positives in the third round of testing, the risk is updated to 88%. The successive Bayesian calculation can be regarded as sequential updating of probabilities. Such updating would not be easy without the idea of the Bayes’ rule or formula.
Sensitivity and Specificity
The sensitivity of a medical diagnostic test is the ability to give correct results for the people who have the disease. Putting it in another way, the sensitivity is the true positive rate, which would be the percentage of sick people who are correctly identified as having the disease. In other words, the sensitivity of a test is the probability of a correct test result for the people with the disease. In our discussion, the sensitivity is the conditional forward probability .
The specificity of a medical diagnostic test is the ability to give correct results for the people who do not have the disease. The specificity is then the true negative rate, which would be the percentage of healthy people who are correctly identified as not having the disease. In other words, the specificity of a test is the probability of a correct test result for healthy people. In our discussion, the specificity is the conditional forward probability .
With the sensitivity being the conditional forward probability , the discussion in this post shows that the sensitivity of a test is not the same as backward conditional probability . The sensitivity may be 90% but the probability can be much lower depending on the prevalence of the disease. The sensitivity only tells us that 90% of the people who have the disease will have a positive result. It does not take into account of the prevalence of the disease (called the base rate). The above calculation shows that the rarer the disease (the lower the base rate), the lower the likelihood that a positive test result is a true positive. Likewise, the more common the disease, the higher the likelihood that a positive test result is a true positive.
In the example discussed here, both the sensitivity and specificity are 90%. This scenario is certainly ideal. In medical testing, the accuracy of a test for a disease may not be the same for the sick people and for the healthy people. For a simple example, let’s say we use chest pain as a criterion to diagnose a heart attack. This would be a very sensitive test since almost all people experiencing heart attack will have chest pain. However, it would be a test with low specificity since there would be plenty of other reasons for the symptom of chest pain.
Thus it is possible that a test may be very accurate for the people who have the disease but nonetheless identify many healthy people as positive. In other words, some tests have high sensitivity but have much lower specificity.
In medical testing, the overriding concern is to use a test with high sensitivity. The reason is that a high true positive rate leads to a low false negative rate. So the goal is to have as few false negative cases as possible in order to correctly diagnose as many sick people as possible. The trade off is that there may be a higher number of false positives, which is considered to be less alarming than missing people who have the disease. The usual practice is that a first test for a disease has high sensitivity but lower specificity. To weed out the false positives, the positives in the first round of testing will use another test that has a higher specificity.

 2017 – Dan Ma
2017 – Dan Ma


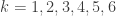


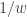




![\displaystyle P[H \lvert -]=\frac{0.891}{0.891+0.001}=\frac{0.891}{0.892}=0.9989=99.89 \%](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+P%5BH+%5Clvert+-%5D%3D%5Cfrac%7B0.891%7D%7B0.891%2B0.001%7D%3D%5Cfrac%7B0.891%7D%7B0.892%7D%3D0.9989%3D99.89+%5C%25&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle P[S \lvert +]=\frac{P[S \text{ and } +]}{P[+]}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+P%5BS+%5Clvert+%2B%5D%3D%5Cfrac%7BP%5BS+%5Ctext%7B+and+%7D+%2B%5D%7D%7BP%5B%2B%5D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle P[S \lvert +]=\frac{P[S] \times P(+ \lvert S)}{P[H] \times P(+ \lvert H)+P[S] \times P(+ \lvert S)}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+P%5BS+%5Clvert+%2B%5D%3D%5Cfrac%7BP%5BS%5D+%5Ctimes+P%28%2B+%5Clvert+S%29%7D%7BP%5BH%5D+%5Ctimes+P%28%2B+%5Clvert+H%29%2BP%5BS%5D+%5Ctimes+P%28%2B+%5Clvert+S%29%7D&bg=ffffff&fg=333333&s=0&c=20201002)

![\displaystyle \begin{aligned} P[S \lvert +]&=\frac{P[S] \times P(+ \lvert S)}{P[H] \times P(+ \lvert H)+P[S] \times P(+ \lvert S)} \\&=\frac{0.0833 \times 0.9}{0.9167 \times 0.1+0.0833 \times 0.9} =0.44989 \approx 45 \% \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+P%5BS+%5Clvert+%2B%5D%26%3D%5Cfrac%7BP%5BS%5D+%5Ctimes+P%28%2B+%5Clvert+S%29%7D%7BP%5BH%5D+%5Ctimes+P%28%2B+%5Clvert+H%29%2BP%5BS%5D+%5Ctimes+P%28%2B+%5Clvert+S%29%7D+%5C%5C%26%3D%5Cfrac%7B0.0833+%5Ctimes+0.9%7D%7B0.9167+%5Ctimes+0.1%2B0.0833+%5Ctimes+0.9%7D+%3D0.44989+%5Capprox+45+%5C%25++%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle \begin{aligned} P[S \lvert +]&=\frac{P[S] \times P(+ \lvert S)}{P[H] \times P(+ \lvert H)+P[S] \times P(+ \lvert S)} \\&=\frac{0.45 \times 0.9}{0.55 \times 0.1+0.45 \times 0.9} =0.88043 \approx 88 \% \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+P%5BS+%5Clvert+%2B%5D%26%3D%5Cfrac%7BP%5BS%5D+%5Ctimes+P%28%2B+%5Clvert+S%29%7D%7BP%5BH%5D+%5Ctimes+P%28%2B+%5Clvert+H%29%2BP%5BS%5D+%5Ctimes+P%28%2B+%5Clvert+S%29%7D+%5C%5C%26%3D%5Cfrac%7B0.45+%5Ctimes+0.9%7D%7B0.55+%5Ctimes+0.1%2B0.45+%5Ctimes+0.9%7D+%3D0.88043+%5Capprox+88+%5C%25++%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)

 and evaluate the integral. For example, when evaluated at
and evaluate the integral. For example, when evaluated at 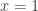 , the integral has value 1. Evaluated at
, the integral has value 1. Evaluated at  , the result is also 1. Evaluated at
, the result is also 1. Evaluated at 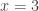 , the result is 2. At
, the result is 2. At 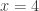 , the result is 6=3!. In fact, if a student remembers a fact about this function (called the gamma function), it is that it gives the factorial when evaluated at the positive integers – the value of the integral is
, the result is 6=3!. In fact, if a student remembers a fact about this function (called the gamma function), it is that it gives the factorial when evaluated at the positive integers – the value of the integral is 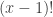 when evaluated at the positive integer
when evaluated at the positive integer 
 . It crops up almost everywhere in mathematics. It has applications in many branches of mathematics including probability and statistics. The integral described above may seem inconsequential, no more than an exercise in an undergraduate course on probability and statistics. We give ample evidence that the gamma function is indeed very consequential, even just in the area of statistics. Our brief tour is through the gamma distribution, a probability distribution that naturally arises from the gamma function. Most of the material cited here is written in various affiliated blogs. Anyone who wants to check out the details can refer to those blogs. Links will be given at the appropriate places.
. It crops up almost everywhere in mathematics. It has applications in many branches of mathematics including probability and statistics. The integral described above may seem inconsequential, no more than an exercise in an undergraduate course on probability and statistics. We give ample evidence that the gamma function is indeed very consequential, even just in the area of statistics. Our brief tour is through the gamma distribution, a probability distribution that naturally arises from the gamma function. Most of the material cited here is written in various affiliated blogs. Anyone who wants to check out the details can refer to those blogs. Links will be given at the appropriate places. 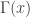 is defined for
is defined for 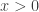 according to the integral described above. A natural question: how do we know that the integral converges, i.e. the integral always gives a valid number as result? How do we know that the integral does not give infinity as result? The integral does converge for all
according to the integral described above. A natural question: how do we know that the integral converges, i.e. the integral always gives a valid number as result? How do we know that the integral does not give infinity as result? The integral does converge for all 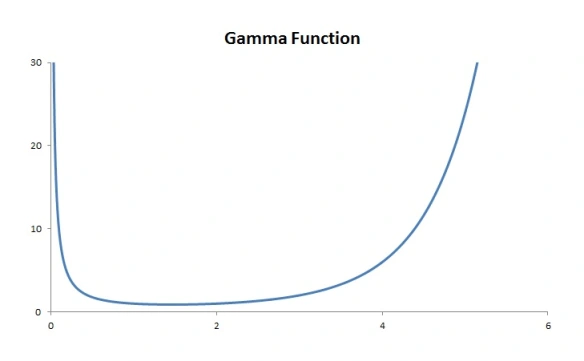
 . Thus the graph of the gamma function goes up without bound as
. Thus the graph of the gamma function goes up without bound as  .
. . To evaluate the function at the higher integers, the integral would required integration by parts. In fact, using integration by parts, the following recursive relation is established.
. To evaluate the function at the higher integers, the integral would required integration by parts. In fact, using integration by parts, the following recursive relation is established.

 , we have
, we have  . Furthermore, the relation (2b) gives a way to extend the gamma function to the negative numbers. For example,
. Furthermore, the relation (2b) gives a way to extend the gamma function to the negative numbers. For example,  would be evaluated by
would be evaluated by  . Based on this idea, for any real number in the interval
. Based on this idea, for any real number in the interval 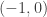 ,
,  ,
, 
 .
.
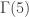 , which is 4! = 24. The integrand would be the expression
, which is 4! = 24. The integrand would be the expression  . Let’s graph this expression over all
. Let’s graph this expression over all 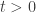 .
.
 for
for 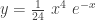 .
.
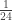 . The second curve is just a compression of the first one. But this time the area under the curve is 1. This means that
. The second curve is just a compression of the first one. But this time the area under the curve is 1. This means that 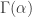 . The following is always a probability density function.
. The following is always a probability density function.
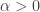 . The number
. The number  to work as a scale parameter.
to work as a scale parameter.
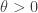 . Thus the gamma distribution has two parameters
. Thus the gamma distribution has two parameters 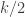 and scale parameter 2 with
and scale parameter 2 with 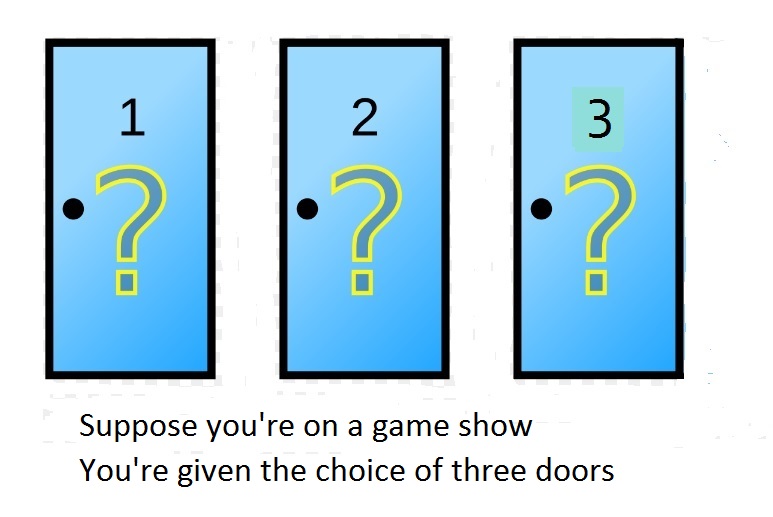














 coins and player B has
coins and player B has  coins. So there are
coins. So there are  coins between them. In each play of the game, a fair coin is tossed. If the result of the coin toss is head, player A collects 1 coin from B. If the result of the coin toss is tail, player A pays B 1 coin. The game continues until one of the players has all the coins. What is the probability that player A ends up with all the coins? What is the probability that player B ends up with all the coins?
coins between them. In each play of the game, a fair coin is tossed. If the result of the coin toss is head, player A collects 1 coin from B. If the result of the coin toss is tail, player A pays B 1 coin. The game continues until one of the players has all the coins. What is the probability that player A ends up with all the coins? What is the probability that player B ends up with all the coins?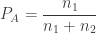 .
. .
. be the probability that the coin toss results in a head. Let
be the probability that the coin toss results in a head. Let 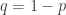 . Suppose that there are
. Suppose that there are  coins initially between player A and player B.
coins initially between player A and player B.  be the probability that player A will own all the
be the probability that player A will own all the  coins and player B starts with
coins and player B starts with  coins. On the other hand, let
coins. On the other hand, let 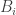 be the probability that player B will own all the
be the probability that player B will own all the  and to show that
and to show that  . The last point, though seems like common sense, is not entirely trivial. It basically says that the game will end in finite number of moves (it cannot go on indefinitely).
. The last point, though seems like common sense, is not entirely trivial. It basically says that the game will end in finite number of moves (it cannot go on indefinitely).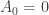 and
and  as well as
as well as 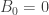 and
and  . In the following derivation,
. In the following derivation,  is the event that the first toss is a tail.
is the event that the first toss is a tail. be the event that player A owning all the coins when player A starts the game with
be the event that player A owning all the coins when player A starts the game with  . First condition on the outcome of the first toss of the coin.
. First condition on the outcome of the first toss of the coin.
 and
and  . Note that
. Note that 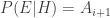 . If the first toss is a head, then player A has
. If the first toss is a head, then player A has 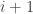 coins and player B would have
coins and player B would have  coins. At that point, the probability of player A owning all the coins would be the same as the probability of winning as if the game begins with player A having
coins. At that point, the probability of player A owning all the coins would be the same as the probability of winning as if the game begins with player A having 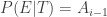 . Plug these into (1), we have:
. Plug these into (1), we have:
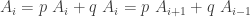
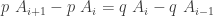

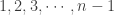 for
for  equations.
equations.![\displaystyle \begin{aligned} &A_{2}-A_{1}=\frac{q}{p} \ (A_1-A_{0})=\frac{q}{p} \ A_1 \\&A_{3}-A_{2}=\frac{q}{p} \ (A_2-A_{1})=\bigg[ \frac{q}{p} \biggr]^2 \ A_1 \\&\ \ \ \cdots \\&A_{i}-A_{i-1}=\frac{q}{p} \ (A_{i-1}-A_{i-2})=\bigg[ \frac{q}{p} \biggr]^{i-1} \ A_1 \\&\ \ \ \cdots \\&A_{n}-A_{n-1}=\frac{q}{p} \ (A_{n-1}-A_{n-2})=\bigg[ \frac{q}{p} \biggr]^{n-1} \ A_1 \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%26A_%7B2%7D-A_%7B1%7D%3D%5Cfrac%7Bq%7D%7Bp%7D+%5C+%28A_1-A_%7B0%7D%29%3D%5Cfrac%7Bq%7D%7Bp%7D+%5C+A_1+%5C%5C%26A_%7B3%7D-A_%7B2%7D%3D%5Cfrac%7Bq%7D%7Bp%7D+%5C+%28A_2-A_%7B1%7D%29%3D%5Cbigg%5B+%5Cfrac%7Bq%7D%7Bp%7D+%5Cbiggr%5D%5E2+%5C+A_1+%5C%5C%26%5C+%5C+%5C+%5Ccdots+%5C%5C%26A_%7Bi%7D-A_%7Bi-1%7D%3D%5Cfrac%7Bq%7D%7Bp%7D+%5C+%28A_%7Bi-1%7D-A_%7Bi-2%7D%29%3D%5Cbigg%5B+%5Cfrac%7Bq%7D%7Bp%7D+%5Cbiggr%5D%5E%7Bi-1%7D+%5C+A_1+%5C%5C%26%5C+%5C+%5C+%5Ccdots+%5C%5C%26A_%7Bn%7D-A_%7Bn-1%7D%3D%5Cfrac%7Bq%7D%7Bp%7D+%5C+%28A_%7Bn-1%7D-A_%7Bn-2%7D%29%3D%5Cbigg%5B+%5Cfrac%7Bq%7D%7Bp%7D+%5Cbiggr%5D%5E%7Bn-1%7D+%5C+A_1+%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)
 equations produces the following equations.
equations produces the following equations.![\displaystyle A_i-A_1=A_1 \ \biggl[\frac{q}{p}+\bigg( \frac{q}{p} \biggr)^{2}+\cdots+\bigg( \frac{q}{p} \biggr)^{i-1} \biggr]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+A_i-A_1%3DA_1+%5C+%5Cbiggl%5B%5Cfrac%7Bq%7D%7Bp%7D%2B%5Cbigg%28+%5Cfrac%7Bq%7D%7Bp%7D+%5Cbiggr%29%5E%7B2%7D%2B%5Ccdots%2B%5Cbigg%28+%5Cfrac%7Bq%7D%7Bp%7D+%5Cbiggr%29%5E%7Bi-1%7D+%5Cbiggr%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle A_i=A_1 \ \biggl[1+\frac{q}{p}+\bigg( \frac{q}{p} \biggr)^{2}+\cdots+\bigg( \frac{q}{p} \biggr)^{i-1} \biggr] \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ (3)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+A_i%3DA_1+%5C+%5Cbiggl%5B1%2B%5Cfrac%7Bq%7D%7Bp%7D%2B%5Cbigg%28+%5Cfrac%7Bq%7D%7Bp%7D+%5Cbiggr%29%5E%7B2%7D%2B%5Ccdots%2B%5Cbigg%28+%5Cfrac%7Bq%7D%7Bp%7D+%5Cbiggr%29%5E%7Bi-1%7D+%5Cbiggr%5D+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%283%29&bg=ffffff&fg=333333&s=0&c=20201002)
 or
or  . The first case means
. The first case means 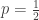 and the second case means
and the second case means 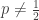 . The following is an expression for
. The following is an expression for 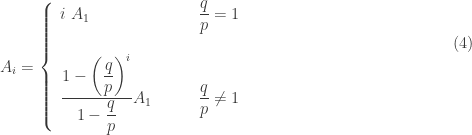
 . Plugging
. Plugging 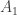 :
:

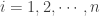 . For the case of
. For the case of 
 , it is clear that
, it is clear that 
 !
!


 or other irrational numbers such as
or other irrational numbers such as 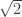 are normal numbers.
are normal numbers.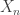 be the number of balls that are required to obtain a repeat. Some of the problems we discuss include the mean (the average number of balls that are to be thrown to get a repeat) and the probability function. We will also show how this random variable is linked to the birthday problem when
be the number of balls that are required to obtain a repeat. Some of the problems we discuss include the mean (the average number of balls that are to be thrown to get a repeat) and the probability function. We will also show how this random variable is linked to the birthday problem when 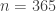 .
. .
.![\displaystyle \begin{aligned} p_k&=\frac{365}{365} \ \frac{364}{365} \ \frac{363}{365} \cdots \frac{365-(k-1)}{365} \\&=\frac{364}{365} \ \frac{363}{365} \cdots \frac{365-(k-1)}{365} \\&=\biggl[1-\frac{1}{365} \biggr] \ \biggl[1-\frac{2}{365} \biggr] \cdots \biggl[1-\frac{k-1}{365} \biggr] \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ (1) \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+p_k%26%3D%5Cfrac%7B365%7D%7B365%7D+%5C+%5Cfrac%7B364%7D%7B365%7D+%5C+%5Cfrac%7B363%7D%7B365%7D+%5Ccdots+%5Cfrac%7B365-%28k-1%29%7D%7B365%7D+%5C%5C%26%3D%5Cfrac%7B364%7D%7B365%7D+%5C+%5Cfrac%7B363%7D%7B365%7D+%5Ccdots+%5Cfrac%7B365-%28k-1%29%7D%7B365%7D+%5C%5C%26%3D%5Cbiggl%5B1-%5Cfrac%7B1%7D%7B365%7D+%5Cbiggr%5D+%5C+%5Cbiggl%5B1-%5Cfrac%7B2%7D%7B365%7D+%5Cbiggr%5D+%5Ccdots+%5Cbiggl%5B1-%5Cfrac%7Bk-1%7D%7B365%7D+%5Cbiggr%5D+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%281%29+%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)
 . The reasoning for the first line is that there are 365 choices to be picked in the first selection. Each subsequent random selection has to avoid the previous birthday, thus 364 choices for the second person and only
. The reasoning for the first line is that there are 365 choices to be picked in the first selection. Each subsequent random selection has to avoid the previous birthday, thus 364 choices for the second person and only 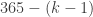 choices for the
choices for the  until reaching the smallest
until reaching the smallest 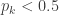 and
and 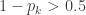 . The calculation should be done using software (Excel for example). The smallest
. The calculation should be done using software (Excel for example). The smallest 

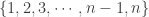 with replacement until a number is chosen twice (until a repeat occurs). Similarly, let
with replacement until a number is chosen twice (until a repeat occurs). Similarly, let  be the probability that in
be the probability that in ![\displaystyle \begin{aligned} p_{n,k}&=\frac{n}{n} \ \frac{n-1}{n} \ \frac{n-2}{n} \cdots \frac{n-(k-1)}{n} \\&=\frac{n-1}{n} \ \frac{n-2}{n} \cdots \frac{n-(k-1)}{n} \\&=\biggl[1-\frac{1}{n} \biggr] \ \biggl[1-\frac{2}{n} \biggr] \cdots \biggl[1-\frac{k-1}{n} \biggr] \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ (2) \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+p_%7Bn%2Ck%7D%26%3D%5Cfrac%7Bn%7D%7Bn%7D+%5C+%5Cfrac%7Bn-1%7D%7Bn%7D+%5C+%5Cfrac%7Bn-2%7D%7Bn%7D+%5Ccdots+%5Cfrac%7Bn-%28k-1%29%7D%7Bn%7D+%5C%5C%26%3D%5Cfrac%7Bn-1%7D%7Bn%7D+%5C+%5Cfrac%7Bn-2%7D%7Bn%7D+%5Ccdots+%5Cfrac%7Bn-%28k-1%29%7D%7Bn%7D+%5C%5C%26%3D%5Cbiggl%5B1-%5Cfrac%7B1%7D%7Bn%7D+%5Cbiggr%5D+%5C+%5Cbiggl%5B1-%5Cfrac%7B2%7D%7Bn%7D+%5Cbiggr%5D+%5Ccdots+%5Cbiggl%5B1-%5Cfrac%7Bk-1%7D%7Bn%7D+%5Cbiggr%5D+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%282%29+%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)
 be the number of rolls to obtain the repeated value. Find the probability function
be the number of rolls to obtain the repeated value. Find the probability function ![P[X_6=k]](https://s0.wp.com/latex.php?latex=P%5BX_6%3Dk%5D&bg=ffffff&fg=333333&s=0&c=20201002) where
where  .
.
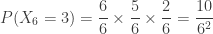



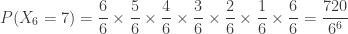
 rolls are distinct and the last roll must be one of the previous values.
rolls are distinct and the last roll must be one of the previous values. 
![P[X_n=k]](https://s0.wp.com/latex.php?latex=P%5BX_n%3Dk%5D&bg=ffffff&fg=333333&s=0&c=20201002) .
.![\displaystyle \begin{aligned} P[X_n=k]&=\frac{n}{n} \times \frac{n-1}{n} \times \cdots \times \frac{n-(k-2)}{n} \times \frac{k-1}{n} \\&=\frac{n-1}{n} \times \cdots \times \frac{n-(k-2)}{n} \times \frac{k-1}{n} \\&=\frac{(n-1) \times (n-2) \times \cdots \times (n-(k-2)) \times (k-1)}{n^{k-1}} \\&=\biggl[1-\frac{1}{n} \biggr] \times \biggl[1-\frac{2}{n} \biggr] \times \cdots \times \biggl[1-\frac{k-2}{n}\biggr] \times \frac{k-1}{n} \ \ \ \ \ \ \ (3) \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+P%5BX_n%3Dk%5D%26%3D%5Cfrac%7Bn%7D%7Bn%7D+%5Ctimes+%5Cfrac%7Bn-1%7D%7Bn%7D+%5Ctimes+%5Ccdots+%5Ctimes+%5Cfrac%7Bn-%28k-2%29%7D%7Bn%7D+%5Ctimes+%5Cfrac%7Bk-1%7D%7Bn%7D+%5C%5C%26%3D%5Cfrac%7Bn-1%7D%7Bn%7D+%5Ctimes+%5Ccdots+%5Ctimes+%5Cfrac%7Bn-%28k-2%29%7D%7Bn%7D+%5Ctimes+%5Cfrac%7Bk-1%7D%7Bn%7D+%5C%5C%26%3D%5Cfrac%7B%28n-1%29+%5Ctimes+%28n-2%29+%5Ctimes+%5Ccdots+%5Ctimes+%28n-%28k-2%29%29+%5Ctimes+%28k-1%29%7D%7Bn%5E%7Bk-1%7D%7D+%5C%5C%26%3D%5Cbiggl%5B1-%5Cfrac%7B1%7D%7Bn%7D+%5Cbiggr%5D+%5Ctimes+%5Cbiggl%5B1-%5Cfrac%7B2%7D%7Bn%7D+%5Cbiggr%5D+%5Ctimes+%5Ccdots+%5Ctimes+%5Cbiggl%5B1-%5Cfrac%7Bk-2%7D%7Bn%7D%5Cbiggr%5D+%5Ctimes+%5Cfrac%7Bk-1%7D%7Bn%7D++%5C+%5C+%5C+%5C+%5C+%5C+%5C+%283%29+%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)
 .
.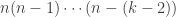 ways. There are
ways. There are ![E[X_n]](https://s0.wp.com/latex.php?latex=E%5BX_n%5D&bg=ffffff&fg=333333&s=0&c=20201002) can be derived accordingly. For the case of
can be derived accordingly. For the case of ![E[X_{365}]=24.62](https://s0.wp.com/latex.php?latex=E%5BX_%7B365%7D%5D%3D24.62&bg=ffffff&fg=333333&s=0&c=20201002) (calculated by programming the probability function in Excel). On average it will be required to sample about 25 people to obtain a repeated birthday.
(calculated by programming the probability function in Excel). On average it will be required to sample about 25 people to obtain a repeated birthday.![P[X_n>k]](https://s0.wp.com/latex.php?latex=P%5BX_n%3Ek%5D&bg=ffffff&fg=333333&s=0&c=20201002) . This is the probability that it will take throwing more than
. This is the probability that it will take throwing more than ![P[X_n \le k]](https://s0.wp.com/latex.php?latex=P%5BX_n+%5Cle+k%5D&bg=ffffff&fg=333333&s=0&c=20201002) by summing the individual probabilities via (3). This is a workable approach using software. There is another way that is more informative. For the event
by summing the individual probabilities via (3). This is a workable approach using software. There is another way that is more informative. For the event  to happen, the first
to happen, the first ![\displaystyle P[X_n>k]=\biggl[1-\frac{1}{n} \biggr] \ \biggl[1-\frac{2}{n} \biggr] \cdots \biggl[1-\frac{k-1}{n} \biggr] \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ (4)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+P%5BX_n%3Ek%5D%3D%5Cbiggl%5B1-%5Cfrac%7B1%7D%7Bn%7D+%5Cbiggr%5D+%5C+%5Cbiggl%5B1-%5Cfrac%7B2%7D%7Bn%7D+%5Cbiggr%5D+%5Ccdots+%5Cbiggl%5B1-%5Cfrac%7Bk-1%7D%7Bn%7D+%5Cbiggr%5D+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%284%29&bg=ffffff&fg=333333&s=0&c=20201002)
 . What is the median of
. What is the median of ![P[X_{365} \le k]](https://s0.wp.com/latex.php?latex=P%5BX_%7B365%7D+%5Cle+k%5D&bg=ffffff&fg=333333&s=0&c=20201002) is at least 0.5. Note that
is at least 0.5. Note that ![P[X_{365}>k]](https://s0.wp.com/latex.php?latex=P%5BX_%7B365%7D%3Ek%5D&bg=ffffff&fg=333333&s=0&c=20201002) is identical to
is identical to 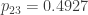 and
and  . Thus the median of
. Thus the median of  . In contrast, the mean of
. In contrast, the mean of ![\begin{array}{ccccccc} k & \text{ } & P[X_{365}>k] & \text{ } & P[X_{365} \le k] & \text{ } & \text{Percentile} \\ \text{ } & \text{ } & \text{ } & \text{ } & \text{ } & \\ 14 & \text{ } & 0.77690 & & 0.22310 & \\ 15 & \text{ } & 0.74710 & & 0.25290 & \text{ } & \text{25th Percentile} \\ 16 & \text{ } & 0.71640 & & 0.28360 & \\ \text{ } & \text{ } & \text{ } & \text{ } & \text{ } & \\ 22 & \text{ } & 0.52430 & & 0.47570 & \\ 23 & \text{ } & 0.49270 & & 0.50730 & \text{ } & \text{50th Percentile} \\ 24 & \text{ } & 0.46166 & & 0.53834 & \\ \text{ } & \text{ } & \text{ } & \text{ } & \text{ } & \\ 31 & \text{ } & 0.26955 & & 0.73045 & \\ 32 & \text{ } & 0.24665 & & 0.75335 & \text{ } & \text{75th Percentile} \\ 33 & \text{ } & 0.22503 & & 0.77497 & \\ \text{ } & \text{ } & \text{ } & \text{ } & \text{ } & \\ 40 & \text{ } & 0.10877 & & 0.89123 & \\ 41 & \text{ } & 0.09685 & & 0.90315 & \text{ } & \text{90th Percentile} \\ 42 & \text{ } & 0.08597 & & 0.91403 & \\ \text{ } & \text{ } & \text{ } & \text{ } & \text{ } & \\ 46 & \text{ } & 0.05175 & & 0.94825 & \\ 47 & \text{ } & 0.04523 & & 0.95477 & \text{ } & \text{95th Percentile} \\ 48 & \text{ } & 0.03940 & & 0.96060 & \\ \text{ } & \text{ } & \text{ } & \text{ } & \text{ } & \\ 56 & \text{ } & 0.01167 & & 0.98833 & \\ 57 & \text{ } & 0.00988 & & 0.99012 & \text{ } & \text{99th Percentile} \\ 58 & \text{ } & 0.00834 & & 0.99166 & \\ \end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Bccccccc%7D++++k+%26++%5Ctext%7B+%7D+%26+P%5BX_%7B365%7D%3Ek%5D++%26+%5Ctext%7B+%7D+%26+P%5BX_%7B365%7D+%5Cle+k%5D+%26+%5Ctext%7B+%7D+%26+%5Ctext%7BPercentile%7D+%5C%5C++++%5Ctext%7B+%7D+%26+++%5Ctext%7B+%7D+%26+%5Ctext%7B+%7D+%26+%5Ctext%7B+%7D+%26+%5Ctext%7B+%7D+%26++%5C%5C+++14+%26+++%5Ctext%7B+%7D+%26+0.77690+%26++%26+0.22310+%26++%5C%5C+++15+%26+++%5Ctext%7B+%7D+%26+0.74710+%26++%26+0.25290+%26+%5Ctext%7B+%7D+%26+%5Ctext%7B25th+Percentile%7D+%5C%5C+++16+%26+++%5Ctext%7B+%7D+%26+0.71640+%26++%26+0.28360+%26++%5C%5C++%5Ctext%7B+%7D+%26+++%5Ctext%7B+%7D+%26+%5Ctext%7B+%7D+%26+%5Ctext%7B+%7D+%26+%5Ctext%7B+%7D+%26++%5C%5C+++22+%26+++%5Ctext%7B+%7D+%26+0.52430+%26++%26+0.47570+%26++%5C%5C+++23+%26+++%5Ctext%7B+%7D+%26+0.49270+%26++%26+0.50730+%26+%5Ctext%7B+%7D+%26+%5Ctext%7B50th+Percentile%7D++%5C%5C+++24+%26+++%5Ctext%7B+%7D+%26+0.46166+%26++%26+0.53834+%26++%5C%5C++%5Ctext%7B+%7D+%26+++%5Ctext%7B+%7D+%26+%5Ctext%7B+%7D+%26+%5Ctext%7B+%7D+%26+%5Ctext%7B+%7D+%26++%5C%5C+++31+%26+++%5Ctext%7B+%7D+%26+0.26955+%26++%26+0.73045+%26++%5C%5C+++32+%26+++%5Ctext%7B+%7D+%26+0.24665+%26++%26+0.75335+%26+%5Ctext%7B+%7D+%26+%5Ctext%7B75th+Percentile%7D+%5C%5C+++++++++33+%26+++%5Ctext%7B+%7D+%26+0.22503+%26++%26+0.77497+%26++%5C%5C++%5Ctext%7B+%7D+%26+++%5Ctext%7B+%7D+%26+%5Ctext%7B+%7D+%26+%5Ctext%7B+%7D+%26+%5Ctext%7B+%7D+%26++%5C%5C+++40+%26+++%5Ctext%7B+%7D+%26+0.10877+%26++%26+0.89123+%26++%5C%5C+++41+%26+++%5Ctext%7B+%7D+%26+0.09685+%26++%26+0.90315+%26+%5Ctext%7B+%7D+%26+%5Ctext%7B90th+Percentile%7D+%5C%5C+++42+%26+++%5Ctext%7B+%7D+%26+0.08597+%26++%26+0.91403+%26++%5C%5C++%5Ctext%7B+%7D+%26+++%5Ctext%7B+%7D+%26+%5Ctext%7B+%7D+%26+%5Ctext%7B+%7D+%26+%5Ctext%7B+%7D+%26++%5C%5C+++46+%26+++%5Ctext%7B+%7D+%26+0.05175+%26++%26+0.94825+%26++%5C%5C+++47+%26+++%5Ctext%7B+%7D+%26+0.04523+%26++%26+0.95477+%26+%5Ctext%7B+%7D+%26+%5Ctext%7B95th+Percentile%7D+%5C%5C++++48+%26++%5Ctext%7B+%7D+%26+0.03940+%26++%26+0.96060+%26++%5C%5C++%5Ctext%7B+%7D+%26+++%5Ctext%7B+%7D+%26+%5Ctext%7B+%7D+%26+%5Ctext%7B+%7D+%26+%5Ctext%7B+%7D+%26++%5C%5C++++56+%26++%5Ctext%7B+%7D+%26+0.01167+%26++%26+0.98833+%26++%5C%5C++57+%26++%5Ctext%7B+%7D+%26+0.00988+%26++%26+0.99012+%26+%5Ctext%7B+%7D+%26+%5Ctext%7B99th+Percentile%7D+%5C%5C++58+%26++%5Ctext%7B+%7D+%26+0.00834+%26++%26+0.99166+%26++%5C%5C++++++%5Cend%7Barray%7D&bg=ffffff&fg=333333&s=0&c=20201002)

 distinct coupons where
distinct coupons where  . It turns out that this special case only requires a minor tweak to the case of collecting the entire set. Our strategy then is to focus on the main case. The special case will be discussed at the end of the post.
. It turns out that this special case only requires a minor tweak to the case of collecting the entire set. Our strategy then is to focus on the main case. The special case will be discussed at the end of the post. . Selecting a number at random from
. Selecting a number at random from 
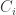 is the additional selections from
is the additional selections from  is the number of random selections to get a number that is distinct from the two distinct numbers obtained up to that point.
is the number of random selections to get a number that is distinct from the two distinct numbers obtained up to that point.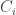 involves repeated sampling until some criterion is reached, thus resembling a geometric random variable. Indeed they are. As the sampling continues and as more distinct values are obtained, it is not as easy to obtain a new number. After
involves repeated sampling until some criterion is reached, thus resembling a geometric random variable. Indeed they are. As the sampling continues and as more distinct values are obtained, it is not as easy to obtain a new number. After 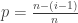 . As geometric random variables, each
. As geometric random variables, each ![\displaystyle E[C_i]=\frac{1}{p}=\frac{n}{n-(i-1)}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5BC_i%5D%3D%5Cfrac%7B1%7D%7Bp%7D%3D%5Cfrac%7Bn%7D%7Bn-%28i-1%29%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle Var[C_i]=\frac{1-p}{p^2}=\frac{n(i-1)}{[n-(i-1)]^2}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+Var%5BC_i%5D%3D%5Cfrac%7B1-p%7D%7Bp%5E2%7D%3D%5Cfrac%7Bn%28i-1%29%7D%7B%5Bn-%28i-1%29%5D%5E2%7D&bg=ffffff&fg=333333&s=0&c=20201002)
 . Note that the random variables
. Note that the random variables ![\displaystyle E[X_n]=\sum \limits_{i=1}^n E[C_i]=\sum \limits_{i=1}^n \frac{n}{n-(i-1)} \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5BX_n%5D%3D%5Csum+%5Climits_%7Bi%3D1%7D%5En+E%5BC_i%5D%3D%5Csum+%5Climits_%7Bi%3D1%7D%5En+%5Cfrac%7Bn%7D%7Bn-%28i-1%29%7D+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%281%29&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle Var[X_n]=\sum \limits_{i=1}^n Var[C_i]=\sum \limits_{i=1}^n \frac{n(i-1)}{[n-(i-1)]^2} \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+Var%5BX_n%5D%3D%5Csum+%5Climits_%7Bi%3D1%7D%5En+Var%5BC_i%5D%3D%5Csum+%5Climits_%7Bi%3D1%7D%5En+%5Cfrac%7Bn%28i-1%29%7D%7B%5Bn-%28i-1%29%5D%5E2%7D+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%282%29&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle E[X_n]=n \ \biggl[\frac{1}{n}+ \cdots + \frac{1}{3}+ \frac{1}{2} + 1\biggr]=n \ H_n \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ (3)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5BX_n%5D%3Dn+%5C+%5Cbiggl%5B%5Cfrac%7B1%7D%7Bn%7D%2B+%5Ccdots+%2B+%5Cfrac%7B1%7D%7B3%7D%2B+%5Cfrac%7B1%7D%7B2%7D+%2B+1%5Cbiggr%5D%3Dn+%5C+H_n++%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%283%29&bg=ffffff&fg=333333&s=0&c=20201002)
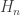 is the partial sum of the harmonic series. Note that
is the partial sum of the harmonic series. Note that  as
as  . Thus
. Thus ![E[X_n] \rightarrow \infty](https://s0.wp.com/latex.php?latex=E%5BX_n%5D+%5Crightarrow+%5Cinfty&bg=ffffff&fg=333333&s=0&c=20201002) as
as ![\begin{array}{cccccc} \text{Number of} & \text{ } & \text{Expected Number of Trials} & \text{ } & \text{Expected Total Number} & \\ \text{Coupons} & \text{ } & \text{per Coupon} & \text{ } & \text{of Trials (rounded up)} & \\ n & \text{ } & E[H_n] & \text{ } & E[X_n] & \\ \text{ } & \text{ } & \text{ } & \text{ } & \text{ } & \\ 1 & \text{ } & 1.0000 & & 1 & \\ 2 & \text{ } & 1.5000 & & 3 & \\ 3 & \text{ } & 1.8333 & & 6 & \\ 4 & \text{ } & 2.0833 & & 9 & \\ 5 & \text{ } & 2.2833 & & 12 & \\ 6 & \text{ } & 2.4500 & & 15 & \\ 7 & \text{ } & 2.5929 & & 19 & \\ 8 & \text{ } & 2.7179 & & 22 & \\ 9 & \text{ } & 2.8290 & & 26 & \\ 10 & \text{ } & 2.9290 & & 30 & \\ 20 & \text{ } & 3.5977 & & 72 & \\ 30 & \text{ } & 3.9950 & & 120 & \\ 40 & \text{ } & 4.2785 & & 172 & \\ 50 & \text{ } & 4.4992 & & 225 & \\ 60 & \text{ } & 4.6799 & & 281 & \\ 70 & \text{ } & 4.8328 & & 339 & \\ 80 & \text{ } & 4.9655 & & 398 & \\ 90 & \text{ } & 5.0826 & & 458 & \\ 100 & \text{ } & 5.1874 & & 519 & \\ \end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Bcccccc%7D++++%5Ctext%7BNumber+of%7D+%26++%5Ctext%7B+%7D+%26+%5Ctext%7BExpected+Number+of+Trials%7D++%26+%5Ctext%7B+%7D+%26+%5Ctext%7BExpected+Total+Number%7D+%26++%5C%5C++%5Ctext%7BCoupons%7D+%26++%5Ctext%7B+%7D+%26+%5Ctext%7Bper+Coupon%7D++%26+%5Ctext%7B+%7D+%26+%5Ctext%7Bof+Trials+%28rounded+up%29%7D+%26++%5C%5C++++n+%26++%5Ctext%7B+%7D+%26+E%5BH_n%5D++%26+%5Ctext%7B+%7D+%26+E%5BX_n%5D+%26++%5C%5C++%5Ctext%7B+%7D+%26+++%5Ctext%7B+%7D+%26+%5Ctext%7B+%7D+%26+%5Ctext%7B+%7D+%26+%5Ctext%7B+%7D+%26++%5C%5C+++1+%26+++%5Ctext%7B+%7D+%26+1.0000+%26++%26+1+%26++%5C%5C+++2+%26+++%5Ctext%7B+%7D+%26+1.5000+%26++%26+3+%26++%5C%5C+++3+%26+++%5Ctext%7B+%7D+%26+1.8333+%26++%26+6+%26++%5C%5C+++4+%26+++%5Ctext%7B+%7D+%26+2.0833+%26++%26+9+%26++%5C%5C+++5+%26+++%5Ctext%7B+%7D+%26+2.2833+%26++%26+12+%26++%5C%5C+++6+%26+++%5Ctext%7B+%7D+%26+2.4500+%26++%26+15+%26++%5C%5C+++7+%26+++%5Ctext%7B+%7D+%26+2.5929+%26++%26+19+%26++%5C%5C+++8+%26+++%5Ctext%7B+%7D+%26+2.7179+%26++%26+22+%26++%5C%5C+++++++++9+%26+++%5Ctext%7B+%7D+%26+2.8290+%26++%26+26+%26++%5C%5C+++10+%26+++%5Ctext%7B+%7D+%26+2.9290+%26++%26+30+%26++%5C%5C+++20+%26+++%5Ctext%7B+%7D+%26+3.5977+%26++%26+72+%26++%5C%5C+++30+%26+++%5Ctext%7B+%7D+%26+3.9950+%26++%26+120+%26++%5C%5C+++40+%26+++%5Ctext%7B+%7D+%26+4.2785+%26++%26+172+%26++%5C%5C+++50+%26+++%5Ctext%7B+%7D+%26+4.4992+%26++%26+225+%26++%5C%5C++++60+%26++%5Ctext%7B+%7D+%26+4.6799+%26++%26+281+%26++%5C%5C++++70+%26++%5Ctext%7B+%7D+%26+4.8328+%26++%26+339+%26++%5C%5C++80+%26++%5Ctext%7B+%7D+%26+4.9655+%26++%26+398+%26++%5C%5C++90+%26++%5Ctext%7B+%7D+%26+5.0826+%26++%26+458+%26++%5C%5C++100+%26++%5Ctext%7B+%7D+%26+5.1874+%26++%26+519+%26++%5C%5C++++%5Cend%7Barray%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![E[C_{50}]=50](https://s0.wp.com/latex.php?latex=E%5BC_%7B50%7D%5D%3D50&bg=ffffff&fg=333333&s=0&c=20201002) in the 50-coupon case in formula (1). In a simulation of the 50-coupon problem, it took 54 trials to obtain the 50th coupon. To get the 49th coupon, it takes on average 50/2 = 25 trials.
in the 50-coupon case in formula (1). In a simulation of the 50-coupon problem, it took 54 trials to obtain the 50th coupon. To get the 49th coupon, it takes on average 50/2 = 25 trials. be the number of empty cells as a result of randomly assigning
be the number of empty cells as a result of randomly assigning  where
where  .
.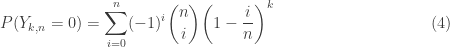

 .
.
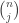 is the binomial coefficient, which is the number of ways to choose
is the binomial coefficient, which is the number of ways to choose  objects out of
objects out of  .
.![P[Y_{k,n}=n-w]](https://s0.wp.com/latex.php?latex=P%5BY_%7Bk%2Cn%7D%3Dn-w%5D&bg=ffffff&fg=333333&s=0&c=20201002) .
. . The event
. The event  means that all
means that all ![P(X_n=k]=P[Y_{k,n}=0 \text{ and } Y_{k-1,n}=1] \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ (6)](https://s0.wp.com/latex.php?latex=P%28X_n%3Dk%5D%3DP%5BY_%7Bk%2Cn%7D%3D0+%5Ctext%7B+and+%7D+Y_%7Bk-1%2Cn%7D%3D1%5D++%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%286%29&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle \begin{aligned} P(X_n=k]&=P[Y_{k,n}=0 \text{ and } Y_{k-1,n}=1] \\&=P[Y_{k,n}=0 \ \lvert \ Y_{k-1,n}=1] \times P[Y_{k-1,n}=1] \\&=\frac{1}{n} \times \binom{n}{1} \sum \limits_{i=0}^{n-1} (-1)^i \binom{n-1}{i} \biggl[ 1-\frac{1+i}{n} \biggr]^{k-1} \\&=\sum \limits_{i=0}^{n-1} (-1)^i \binom{n-1}{i} \biggl[ 1-\frac{1+i}{n} \biggr]^{k-1} \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ (7) \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+P%28X_n%3Dk%5D%26%3DP%5BY_%7Bk%2Cn%7D%3D0+%5Ctext%7B+and+%7D+Y_%7Bk-1%2Cn%7D%3D1%5D+%5C%5C%26%3DP%5BY_%7Bk%2Cn%7D%3D0+%5C+%5Clvert+%5C+Y_%7Bk-1%2Cn%7D%3D1%5D+%5Ctimes+P%5BY_%7Bk-1%2Cn%7D%3D1%5D+%5C%5C%26%3D%5Cfrac%7B1%7D%7Bn%7D+%5Ctimes+%5Cbinom%7Bn%7D%7B1%7D+%5Csum+%5Climits_%7Bi%3D0%7D%5E%7Bn-1%7D+%28-1%29%5Ei+%5Cbinom%7Bn-1%7D%7Bi%7D+%5Cbiggl%5B+1-%5Cfrac%7B1%2Bi%7D%7Bn%7D+%5Cbiggr%5D%5E%7Bk-1%7D+%5C%5C%26%3D%5Csum+%5Climits_%7Bi%3D0%7D%5E%7Bn-1%7D+%28-1%29%5Ei+%5Cbinom%7Bn-1%7D%7Bi%7D+%5Cbiggl%5B+1-%5Cfrac%7B1%2Bi%7D%7Bn%7D+%5Cbiggr%5D%5E%7Bk-1%7D+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%287%29+%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![P[X_6>15]=1-P[6 \le X_6 \le 14]](https://s0.wp.com/latex.php?latex=P%5BX_6%3E15%5D%3D1-P%5B6+%5Cle+X_6+%5Cle+14%5D&bg=ffffff&fg=333333&s=0&c=20201002) .
.
![\displaystyle E[X_6]=6 \ \biggl[ 1 + \frac{1}{2}+\frac{1}{3}+\frac{1}{4}+\frac{1}{5}+\frac{1}{6} \biggr]=6 \times 2.45 = 14.7 \approx 15](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5BX_6%5D%3D6+%5C+%5Cbiggl%5B+1+%2B+%5Cfrac%7B1%7D%7B2%7D%2B%5Cfrac%7B1%7D%7B3%7D%2B%5Cfrac%7B1%7D%7B4%7D%2B%5Cfrac%7B1%7D%7B5%7D%2B%5Cfrac%7B1%7D%7B6%7D+%5Cbiggr%5D%3D6+%5Ctimes+2.45+%3D+14.7+%5Capprox+15&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle Var[X_6]=\sum \limits_{i=1}^6 \frac{6(i-1)}{[6-(i-1)]^2}=38.99](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+Var%5BX_6%5D%3D%5Csum+%5Climits_%7Bi%3D1%7D%5E6+%5Cfrac%7B6%28i-1%29%7D%7B%5B6-%28i-1%29%5D%5E2%7D%3D38.99&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle P[X_6=k]=\sum \limits_{i=0}^{5} (-1)^i \binom{5}{i} \biggl[ 1-\frac{1+i}{6} \biggr]^{k-1}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+P%5BX_6%3Dk%5D%3D%5Csum+%5Climits_%7Bi%3D0%7D%5E%7B5%7D+%28-1%29%5Ei+%5Cbinom%7B5%7D%7Bi%7D+%5Cbiggl%5B+1-%5Cfrac%7B1%2Bi%7D%7B6%7D+%5Cbiggr%5D%5E%7Bk-1%7D&bg=ffffff&fg=333333&s=0&c=20201002)

![P[X_6 \ge 12]=1-P[6 \le X_6 \le 11]=1-0.356206419=0.643793581](https://s0.wp.com/latex.php?latex=P%5BX_6+%5Cge+12%5D%3D1-P%5B6+%5Cle+X_6+%5Cle+11%5D%3D1-0.356206419%3D0.643793581&bg=ffffff&fg=333333&s=0&c=20201002)
![P[X_6 > 15]=1-P[6 \le X_6 \le 15]=1-0.644212739=0.355787261](https://s0.wp.com/latex.php?latex=P%5BX_6+%3E+15%5D%3D1-P%5B6+%5Cle+X_6+%5Cle+15%5D%3D1-0.644212739%3D0.355787261&bg=ffffff&fg=333333&s=0&c=20201002)
 . The following shows the mean and probability function.
. The following shows the mean and probability function.![\displaystyle E[X_{12}]=12 \ \biggl[ 1 + \frac{1}{2}+\frac{1}{3}+\cdots +\frac{1}{12} \biggr]=37.23852814 \approx 38](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5BX_%7B12%7D%5D%3D12+%5C+%5Cbiggl%5B+1+%2B+%5Cfrac%7B1%7D%7B2%7D%2B%5Cfrac%7B1%7D%7B3%7D%2B%5Ccdots+%2B%5Cfrac%7B1%7D%7B12%7D+%5Cbiggr%5D%3D37.23852814+%5Capprox+38&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle P[X_{12}=k]=\sum \limits_{i=0}^{11} (-1)^i \binom{11}{i} \biggl[ 1-\frac{1+i}{12} \biggr]^{k-1}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+P%5BX_%7B12%7D%3Dk%5D%3D%5Csum+%5Climits_%7Bi%3D0%7D%5E%7B11%7D+%28-1%29%5Ei+%5Cbinom%7B11%7D%7Bi%7D+%5Cbiggl%5B+1-%5Cfrac%7B1%2Bi%7D%7B12%7D+%5Cbiggr%5D%5E%7Bk-1%7D&bg=ffffff&fg=333333&s=0&c=20201002)

![P[X_{12} > 25]=1-P[12 \le X_{12} \le 25]=1-0.181898592=0.818101408](https://s0.wp.com/latex.php?latex=P%5BX_%7B12%7D+%3E+25%5D%3D1-P%5B12+%5Cle+X_%7B12%7D+%5Cle+25%5D%3D1-0.181898592%3D0.818101408&bg=ffffff&fg=333333&s=0&c=20201002)
![P[X_{12} > 35]=1-P[12 \le X_{12} \le 35]=1-0.531821149=0.468178851](https://s0.wp.com/latex.php?latex=P%5BX_%7B12%7D+%3E+35%5D%3D1-P%5B12+%5Cle+X_%7B12%7D+%5Cle+35%5D%3D1-0.531821149%3D0.468178851&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle P[X_{12} > 35 \ \lvert \ X_{12} > 25]=\frac{P[X_{12} > 35]}{P[X_{12} > 25]}=\frac{0.468178851}{0.818101408}=0.572274838](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+P%5BX_%7B12%7D+%3E+35+%5C+%5Clvert+%5C+X_%7B12%7D+%3E+25%5D%3D%5Cfrac%7BP%5BX_%7B12%7D+%3E+35%5D%7D%7BP%5BX_%7B12%7D+%3E+25%5D%7D%3D%5Cfrac%7B0.468178851%7D%7B0.818101408%7D%3D0.572274838&bg=ffffff&fg=333333&s=0&c=20201002)
 be the minimum number of purchases such that
be the minimum number of purchases such that 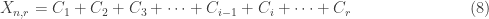
![E[X_{n,r}]](https://s0.wp.com/latex.php?latex=E%5BX_%7Bn%2Cr%7D%5D&bg=ffffff&fg=333333&s=0&c=20201002) and
and ![Var[X_{n,r}]](https://s0.wp.com/latex.php?latex=Var%5BX_%7Bn%2Cr%7D%5D&bg=ffffff&fg=333333&s=0&c=20201002) would be like (1) and (2) except that the summation is through
would be like (1) and (2) except that the summation is through  to happen, exactly
to happen, exactly  cells. In other words, there are exactly
cells. In other words, there are exactly 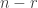 empty cells after throwing
empty cells after throwing  empty cells after throwing
empty cells after throwing ![P[X_{n,r}=k]=P[Y_{k,n}=n-r \text{ and } Y_{k-1,n}=n-r+1] \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ (9)](https://s0.wp.com/latex.php?latex=P%5BX_%7Bn%2Cr%7D%3Dk%5D%3DP%5BY_%7Bk%2Cn%7D%3Dn-r+%5Ctext%7B+and+%7D+Y_%7Bk-1%2Cn%7D%3Dn-r%2B1%5D++%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%289%29&bg=ffffff&fg=333333&s=0&c=20201002)
![P[X_{n,r}=k]](https://s0.wp.com/latex.php?latex=P%5BX_%7Bn%2Cr%7D%3Dk%5D&bg=ffffff&fg=333333&s=0&c=20201002) with the first one coming from the occupancy formula (5).
with the first one coming from the occupancy formula (5).![\displaystyle P[Y_{k-1,n}=n-r+1]=\binom{n}{n-r+1} \sum \limits_{i=0}^{r-1} (-1)^i \binom{r-1}{i} \biggl[ 1-\frac{n-r+1+i}{n} \biggr]^{k-1}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+P%5BY_%7Bk-1%2Cn%7D%3Dn-r%2B1%5D%3D%5Cbinom%7Bn%7D%7Bn-r%2B1%7D+%5Csum+%5Climits_%7Bi%3D0%7D%5E%7Br-1%7D+%28-1%29%5Ei+%5Cbinom%7Br-1%7D%7Bi%7D+%5Cbiggl%5B+1-%5Cfrac%7Bn-r%2B1%2Bi%7D%7Bn%7D+%5Cbiggr%5D%5E%7Bk-1%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle P[Y_{k,n}=n-r \ \lvert \ Y_{k-1,n}=n-r+1]=\frac{n-r+1}{n}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+P%5BY_%7Bk%2Cn%7D%3Dn-r+%5C+%5Clvert+%5C+Y_%7Bk-1%2Cn%7D%3Dn-r%2B1%5D%3D%5Cfrac%7Bn-r%2B1%7D%7Bn%7D&bg=ffffff&fg=333333&s=0&c=20201002)
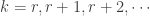 .
.![\displaystyle P[X_{n,r}=k]=\binom{n-1}{r-1} \sum \limits_{i=0}^{r-1} (-1)^i \binom{r-1}{i} \biggl[ 1-\frac{n-r+1+i}{n} \biggr]^{k-1} \ \ \ \ \ \ \ \ (10)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+P%5BX_%7Bn%2Cr%7D%3Dk%5D%3D%5Cbinom%7Bn-1%7D%7Br-1%7D+%5Csum+%5Climits_%7Bi%3D0%7D%5E%7Br-1%7D+%28-1%29%5Ei+%5Cbinom%7Br-1%7D%7Bi%7D+%5Cbiggl%5B+1-%5Cfrac%7Bn-r%2B1%2Bi%7D%7Bn%7D+%5Cbiggr%5D%5E%7Bk-1%7D+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%2810%29&bg=ffffff&fg=333333&s=0&c=20201002)
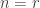 (collecting the entire set of coupons), formula (10) would be identical to (7). The following example demonstrates the calculation.
(collecting the entire set of coupons), formula (10) would be identical to (7). The following example demonstrates the calculation.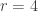 coupons. What is the expected number of purchases to get 4 coupons? What is the probability that it will take more than 6 purchases to get 4 coupons? What is the probability that it will take more than 8 purchases to get 4 coupons? Compare these results with Example 1.
coupons. What is the expected number of purchases to get 4 coupons? What is the probability that it will take more than 6 purchases to get 4 coupons? What is the probability that it will take more than 8 purchases to get 4 coupons? Compare these results with Example 1.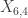 . The mean is:
. The mean is:![\displaystyle E[X_{6,4}]=6 \biggl[ \frac{1}{6}+\frac{1}{5}+\frac{1}{4}+\frac{1}{3} \biggr]=5.7 \approx 6](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5BX_%7B6%2C4%7D%5D%3D6+%5Cbiggl%5B+%5Cfrac%7B1%7D%7B6%7D%2B%5Cfrac%7B1%7D%7B5%7D%2B%5Cfrac%7B1%7D%7B4%7D%2B%5Cfrac%7B1%7D%7B3%7D+%5Cbiggr%5D%3D5.7+%5Capprox+6&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle P[X_{6,4}=k]=\binom{5}{3} \sum \limits_{i=0}^{3} (-1)^i \binom{3}{i} \biggl[ 1-\frac{3+i}{6} \biggr]^{k-1}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+P%5BX_%7B6%2C4%7D%3Dk%5D%3D%5Cbinom%7B5%7D%7B3%7D+%5Csum+%5Climits_%7Bi%3D0%7D%5E%7B3%7D+%28-1%29%5Ei+%5Cbinom%7B3%7D%7Bi%7D+%5Cbiggl%5B+1-%5Cfrac%7B3%2Bi%7D%7B6%7D+%5Cbiggr%5D%5E%7Bk-1%7D&bg=ffffff&fg=333333&s=0&c=20201002)

![P[X_{6,4} > 6]=1-P[12 \le X_{12} \le 25]=1-0.74845679=0.25154321](https://s0.wp.com/latex.php?latex=P%5BX_%7B6%2C4%7D+%3E+6%5D%3D1-P%5B12+%5Cle+X_%7B12%7D+%5Cle+25%5D%3D1-0.74845679%3D0.25154321&bg=ffffff&fg=333333&s=0&c=20201002)
![P[X_{6,4} > 8]=1-P[12 \le X_{12} \le 35]=1-0.928712277=0.071287723](https://s0.wp.com/latex.php?latex=P%5BX_%7B6%2C4%7D+%3E+8%5D%3D1-P%5B12+%5Cle+X_%7B12%7D+%5Cle+35%5D%3D1-0.928712277%3D0.071287723&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle M_{X_n}(t)=\prod \limits_{i=1}^n \frac{[n-(i-1)] e^t}{n-(i-1) e^t} \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ (11)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+M_%7BX_n%7D%28t%29%3D%5Cprod+%5Climits_%7Bi%3D1%7D%5En+%5Cfrac%7B%5Bn-%28i-1%29%5D+e%5Et%7D%7Bn-%28i-1%29+e%5Et%7D+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%2811%29&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle M_{X_{n,r}}(t)=\prod \limits_{i=1}^r \frac{[n-(i-1)] e^t}{n-(i-1) e^t} \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ (12)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+M_%7BX_%7Bn%2Cr%7D%7D%28t%29%3D%5Cprod+%5Climits_%7Bi%3D1%7D%5Er+%5Cfrac%7B%5Bn-%28i-1%29%5D+e%5Et%7D%7Bn-%28i-1%29+e%5Et%7D+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%2812%29&bg=ffffff&fg=333333&s=0&c=20201002)
 possibilities. This number is 67,108,864. So 2 raised to 26 is a little over 67 millions. So the password given by John is not just one password, but is a generic one with over 67 million possibilities. There is a one in 67 million chance in correctly guessing the correct password if John chooses the upper case letters randomly. This is much better odds than winning the Powerball lottery, one in 292,201,338, which one in 292 million. But it is still an undeniably strong password.
possibilities. This number is 67,108,864. So 2 raised to 26 is a little over 67 millions. So the password given by John is not just one password, but is a generic one with over 67 million possibilities. There is a one in 67 million chance in correctly guessing the correct password if John chooses the upper case letters randomly. This is much better odds than winning the Powerball lottery, one in 292,201,338, which one in 292 million. But it is still an undeniably strong password. . Sometimes the notations
. Sometimes the notations  ,
,  and
and 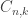 are used. Regardless of the notation, the calculation is
are used. Regardless of the notation, the calculation is 
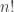 is the product of all the positive integers up to and including
is the product of all the positive integers up to and including  ,
, 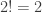 ,
,  ,
,  . To make the formula work correctly, we make
. To make the formula work correctly, we make  .
.
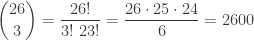


![\displaystyle \begin{array}{rrr} k &\text{ } & P[X=k] \\ \text{ } & \text{ } & \text{ } \\ 0 &\text{ } & 0.00000001 \\ 1 &\text{ } & 0.00000039 \\ 2 &\text{ } & 0.00000484 \\ 3 &\text{ } & 0.00003874 \\ 4 &\text{ } & 0.00022277 \\ 5 &\text{ } & 0.00098020 \\ 6 &\text{ } & 0.00343069 \\ 7 &\text{ } & 0.00980198 \\ 8 &\text{ } & 0.02327971 \\ 9 &\text{ } & 0.04655942 \\ 10 &\text{ } & 0.07915102 \\ 11 &\text{ } & 0.11512876 \\ 12 &\text{ } & 0.14391094 \\ 13 &\text{ } & 0.15498102 \\ 14 &\text{ } & 0.14391094 \\ 15 &\text{ } & 0.11512876 \\ 16 &\text{ } & 0.07915102 \\ 17 &\text{ } & 0.04655942 \\ 18 &\text{ } & 0.02327971 \\ 19 &\text{ } & 0.00980198 \\ 20 &\text{ } & 0.00343069 \\ 21 &\text{ } & 0.00098020 \\ 22 &\text{ } & 0.00022277 \\ 23 &\text{ } & 0.00003874 \\ 24 &\text{ } & 0.00000484 \\ 25 &\text{ } & 0.00000039 \\ 26 &\text{ } & 0.00000001 \\ \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Barray%7D%7Brrr%7D+k+%26%5Ctext%7B+%7D+%26+P%5BX%3Dk%5D++%5C%5C++%5Ctext%7B+%7D+%26+%5Ctext%7B+%7D+%26+%5Ctext%7B+%7D++%5C%5C++0+%26%5Ctext%7B+%7D+%26+0.00000001++%5C%5C+++++1+%26%5Ctext%7B+%7D+%26+0.00000039+++%5C%5C++2+%26%5Ctext%7B+%7D+%26+0.00000484+++%5C%5C++3+%26%5Ctext%7B+%7D+%26+0.00003874+++%5C%5C++4+%26%5Ctext%7B+%7D+%26+0.00022277+++%5C%5C++5+%26%5Ctext%7B+%7D+%26+0.00098020+++%5C%5C++6+%26%5Ctext%7B+%7D+%26+0.00343069+++%5C%5C++7+%26%5Ctext%7B+%7D+%26+0.00980198+++%5C%5C++8+%26%5Ctext%7B+%7D+%26+0.02327971+++%5C%5C++9+%26%5Ctext%7B+%7D+%26+0.04655942+++%5C%5C++10+%26%5Ctext%7B+%7D+%26+0.07915102+++%5C%5C++11+%26%5Ctext%7B+%7D+%26+0.11512876+++%5C%5C++12+%26%5Ctext%7B+%7D+%26+0.14391094+++%5C%5C++13+%26%5Ctext%7B+%7D+%26+0.15498102+++%5C%5C++14+%26%5Ctext%7B+%7D+%26+0.14391094+++%5C%5C++15+%26%5Ctext%7B+%7D+%26+0.11512876+++%5C%5C++16+%26%5Ctext%7B+%7D+%26+0.07915102+++%5C%5C++17+%26%5Ctext%7B+%7D+%26+0.04655942+++%5C%5C++18+%26%5Ctext%7B+%7D+%26+0.02327971+++%5C%5C++19+%26%5Ctext%7B+%7D+%26+0.00980198+++%5C%5C++20+%26%5Ctext%7B+%7D+%26+0.00343069+++%5C%5C++21+%26%5Ctext%7B+%7D+%26+0.00098020+++%5C%5C++22+%26%5Ctext%7B+%7D+%26+0.00022277+++%5C%5C++23+%26%5Ctext%7B+%7D+%26+0.00003874+++%5C%5C++24+%26%5Ctext%7B+%7D+%26+0.00000484+++%5C%5C++25+%26%5Ctext%7B+%7D+%26+0.00000039+++%5C%5C++26+%26%5Ctext%7B+%7D+%26+0.00000001+++%5C%5C++%5Cend%7Barray%7D&bg=ffffff&fg=333333&s=0&c=20201002)
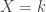 where
where 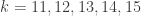 add up to 67.3% of the 67,108,864 possibilities.
add up to 67.3% of the 67,108,864 possibilities. be the number of upper case letters in the 26-character password. Then the random variable
be the number of upper case letters in the 26-character password. Then the random variable 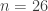 (26 Bernoulli trials) and the probability of success
(26 Bernoulli trials) and the probability of success  in each trial, which is the probability that a character is upper case, assuming that he determines the upper/lower case by a coin toss. The following is the probability function:
in each trial, which is the probability that a character is upper case, assuming that he determines the upper/lower case by a coin toss. The following is the probability function:![\displaystyle P(X=x)=\binom{26}{x} \biggl[\frac{1}{2}\biggr]^x \biggl[\frac{1}{2}\biggr]^{26-x}=\binom{26}{x} \biggl[\frac{1}{2}\biggr]^{26}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+P%28X%3Dx%29%3D%5Cbinom%7B26%7D%7Bx%7D+%5Cbiggl%5B%5Cfrac%7B1%7D%7B2%7D%5Cbiggr%5D%5Ex+%5Cbiggl%5B%5Cfrac%7B1%7D%7B2%7D%5Cbiggr%5D%5E%7B26-x%7D%3D%5Cbinom%7B26%7D%7Bx%7D+%5Cbiggl%5B%5Cfrac%7B1%7D%7B2%7D%5Cbiggr%5D%5E%7B26%7D&bg=ffffff&fg=333333&s=0&c=20201002)
 . The quantity
. The quantity  is the probability that the number of upper case letters is
is the probability that the number of upper case letters is  is the number of ways to choose
is the number of ways to choose 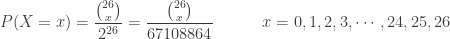

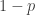 . The random variable
. The random variable 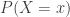 gives the likelihood of achieving
gives the likelihood of achieving  (assuming that the random variable
(assuming that the random variable