Consider a random sample  drawn from a continuous distribution. Rank the sample items in increasing order, resulting in a ranked sample
drawn from a continuous distribution. Rank the sample items in increasing order, resulting in a ranked sample 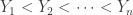 where
where 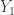 is the smallest sample item,
is the smallest sample item, 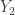 is the second smallest sample item and so on. The items in the ranked sample are called the order statistics. Recently the author of this blog was calculating a conditional probability such as
is the second smallest sample item and so on. The items in the ranked sample are called the order statistics. Recently the author of this blog was calculating a conditional probability such as  . One way to do this is to calculate the distribution function
. One way to do this is to calculate the distribution function 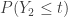 . What about the probability
. What about the probability 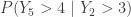 ? Since this one involves two order statistics, the author of this blog initially thought that calculating would require knowing the joint probability distribution of the order statistics
? Since this one involves two order statistics, the author of this blog initially thought that calculating would require knowing the joint probability distribution of the order statistics  . It turns out that a joint distribution may not be needed. Instead, we can calculate a conditional probability such as using multinomial probabilities. In this post, we demonstrate how this is done using examples. Practice problems are found in here.
. It turns out that a joint distribution may not be needed. Instead, we can calculate a conditional probability such as using multinomial probabilities. In this post, we demonstrate how this is done using examples. Practice problems are found in here.
The calculation described here can be lengthy and tedious if the sample size is large. To make the calculation more manageable, the examples here have relatively small sample size. To keep the multinomial probabilities easier to calculate, the random samples are drawn from a uniform distribution. The calculation for larger sample sizes from other distributions is better done using a technology solution. In any case, the calculation described here is a great way to practice working with order statistics and multinomial probabilities.
________________________________________________________________________
The multinomial angle
In this post, the order statistics are resulted from ranking the random sample , which is drawn from a continuous distribution with distribution function 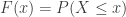 . For the
. For the  th order statistic, the calculation often begins with its distribution function
th order statistic, the calculation often begins with its distribution function  .
.
Here’s the thought process for calculating . In drawing the random sample , make a note of the items 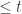 and the items
and the items  . For the event
. For the event 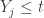 to happen, there must be at least many sample items
to happen, there must be at least many sample items  that are . For the event
that are . For the event  to happen, there can be only at most
to happen, there can be only at most  many sample items . So to calculate , simply find out the probability of having or more sample items . To calculate
many sample items . So to calculate , simply find out the probability of having or more sample items . To calculate 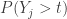 , find the probability of having at most sample items .
, find the probability of having at most sample items .
Both (1) and (2) involve binomial probabilities and are discussed in this previous post. The probability of success is  since we are interested in how many sample items that are . Both the calculations (1) and (2) are based on counting the number of sample items in the two intervals and . It turns out that when the probability that is desired involves more than one
since we are interested in how many sample items that are . Both the calculations (1) and (2) are based on counting the number of sample items in the two intervals and . It turns out that when the probability that is desired involves more than one 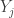 , we can also count the number of sample items that fall into some appropriate intervals and apply some appropriate multinomial probabilities. Let’s use an example to illustrate the idea.
, we can also count the number of sample items that fall into some appropriate intervals and apply some appropriate multinomial probabilities. Let’s use an example to illustrate the idea.
Example 1
Draw a random sample 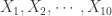 from the uniform distribution
from the uniform distribution  . The resulting order statistics are
. The resulting order statistics are  . Find the following probabilities:
. Find the following probabilities:
For both probabilities, the range of the distribution is broken up into 3 intervals, (0, 2), (2, 3) and (3, 4). Each sample item has probabilities 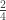 ,
,  , of falling into these intervals, respectively. Multinomial probabilities are calculated on these 3 intervals. It is a matter of counting the numbers of sample items falling into each interval.
, of falling into these intervals, respectively. Multinomial probabilities are calculated on these 3 intervals. It is a matter of counting the numbers of sample items falling into each interval.
The first probability involves the event that there are 4 sample items in the interval (0, 2), 2 sample items in the interval (2, 3) and 4 sample items in the interval (3, 4). Thus the first probability is the following multinomial probability:
For the second probability,  does not have to be greater than 2. Thus there could be 5 sample items less than 2. So we need to add one more case to the above probability (5 sample items to the first interval, 1 sample item to the second interval and 4 sample items to the third interval).
does not have to be greater than 2. Thus there could be 5 sample items less than 2. So we need to add one more case to the above probability (5 sample items to the first interval, 1 sample item to the second interval and 4 sample items to the third interval).
Example 2
Draw a random sample  from the uniform distribution . The resulting order statistics are
from the uniform distribution . The resulting order statistics are 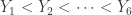 . Find the probability
. Find the probability  .
.
In this problem the range of the distribution is broken up into 3 intervals (0, 1), (1, 3) and (3, 4). Each sample item has probabilities , , of falling into these intervals, respectively. Multinomial probabilities are calculated on these 3 intervals. It is a matter of counting the numbers of sample items falling into each interval. The counting is a little bit more involved here than in the previous example.
The example is to find the probability that both the second order statistic and the fourth order statistic 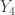 fall into the interval
fall into the interval 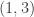 . To solve this, determine how many sample items that fall into the interval
. To solve this, determine how many sample items that fall into the interval  , and
, and 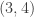 . The following points detail the counting.
. The following points detail the counting.
- For the event
 to happen, there can be at most 1 sample item in the interval .
to happen, there can be at most 1 sample item in the interval .
- For the event
 to happen, there must be at least 4 sample items in the interval
to happen, there must be at least 4 sample items in the interval 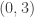 . Thus if the interval has 1 sample item, the interval has at least 3 sample items. If the interval has no sample item, the interval has at least 4 sample items.
. Thus if the interval has 1 sample item, the interval has at least 3 sample items. If the interval has no sample item, the interval has at least 4 sample items.
The following lists out all the cases that satisfy the above two bullet points. The notation ![[a, b, c]](https://s0.wp.com/latex.php?latex=%5Ba%2C+b%2C+c%5D&bg=ffffff&fg=333333&s=0&c=20201002) means that
means that  sample items fall into ,
sample items fall into ,  sample items fall into the interval and
sample items fall into the interval and  sample items fall into the interval . So
sample items fall into the interval . So  . Since the sample items are drawn from , the probabilities of a sample item falling into intervals , and are , and , respectively.
. Since the sample items are drawn from , the probabilities of a sample item falling into intervals , and are , and , respectively.
[0, 4, 2]
[0, 5, 1]
[0, 6, 0]
[1, 3, 2]
[1, 4, 1]
[1, 5, 0]
So in randomly drawing 6 items from the uniform distribution , there is a 40% chance that the second order statistic and the fourth order statistic are between 1 and 3.
________________________________________________________________________
More examples
The method described by the above examples is this. When looking at the event described by the probability problem, the entire range of distribution is broken up into several intervals. Imagine the sample items are randomly being thrown into these interval (i.e. we are sampling from a uniform distribution). Then multinomial probabilities are calculated to account for all the different ways sample items can land into these intervals. The following examples further illustrate this idea.
Example 3
Draw a random sample  from the uniform distribution
from the uniform distribution 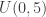 . The resulting order statistics are
. The resulting order statistics are  . Find the following probabilities:
. Find the following probabilities:
The range is broken up into the intervals (0, 1), (1, 3), (3, 4) and (4, 5). The sample items fall into these intervals with probabilities 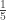 ,
, 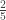 , and . The following details the counting for the event
, and . The following details the counting for the event  :
:
- There are no sample items in (0, 1) since
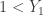 .
.
- Based on
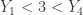 , there are at least one sample item and at most 3 sample items in (0, 3). Thus in the interval (1, 3), there are at least one sample item and at most 3 sample items since there are none in (0, 1).
, there are at least one sample item and at most 3 sample items in (0, 3). Thus in the interval (1, 3), there are at least one sample item and at most 3 sample items since there are none in (0, 1).
- Based on
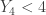 , there are at least 4 sample items in the interval (0, 4). Thus the count in (3, 4) combines with the count in (1, 3) must be at least 4.
, there are at least 4 sample items in the interval (0, 4). Thus the count in (3, 4) combines with the count in (1, 3) must be at least 4.
- The interval (4, 5) simply receives the left over sample items not in the previous intervals.
The notation ![[a, b, c, d]](https://s0.wp.com/latex.php?latex=%5Ba%2C+b%2C+c%2C+d%5D&bg=ffffff&fg=333333&s=0&c=20201002) lists out the counts in the 4 intervals. The following lists out all the cases described by the above 5 bullet points along with the corresponding multinomial probabilities, with two of the probabilities set up.
lists out the counts in the 4 intervals. The following lists out all the cases described by the above 5 bullet points along with the corresponding multinomial probabilities, with two of the probabilities set up.
Summing all the probabilities,  . Out of the 78125 many different ways the 7 sample items can land into these 4 intervals, 6972 of them would satisfy the event .
. Out of the 78125 many different ways the 7 sample items can land into these 4 intervals, 6972 of them would satisfy the event .
++++++++++++++++++++++++++++++++++
We now calculate the second probability in Example 3.
First calculate  . The probability
. The probability  is the probability of having at least 1 sample item less than
is the probability of having at least 1 sample item less than  , which is the complement of the probability of all sample items greater than .
, which is the complement of the probability of all sample items greater than .
The event 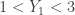 can occur in 16256 ways. Out of these many ways, 6972 of these satisfy the event . Thus we have:
can occur in 16256 ways. Out of these many ways, 6972 of these satisfy the event . Thus we have:
Example 4
Draw a random sample  from the uniform distribution . The resulting order statistics are
from the uniform distribution . The resulting order statistics are  . Consider the conditional random variable
. Consider the conditional random variable 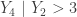 . For this conditional distribution, find the following:
. For this conditional distribution, find the following:
where  . Note that
. Note that 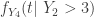 is the density function of .
is the density function of .
Note that
In finding  , the range (0, 5) is broken up into 3 intervals (0, 3), (3, t) and (t, 5). The sample items fall into these intervals with probabilities
, the range (0, 5) is broken up into 3 intervals (0, 3), (3, t) and (t, 5). The sample items fall into these intervals with probabilities 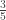 ,
, 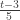 and
and 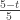 .
.
Since 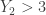 , there is at most 1 sample item in the interval (0, 3). Since
, there is at most 1 sample item in the interval (0, 3). Since  , there are at least 4 sample items in the interval (0, t). So the count in the interval (3, t) and the count in (0, 3) should add up to 4 or more items. The following shows all the cases for the event
, there are at least 4 sample items in the interval (0, t). So the count in the interval (3, t) and the count in (0, 3) should add up to 4 or more items. The following shows all the cases for the event 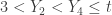 along with the corresponding multinomial probabilities.
along with the corresponding multinomial probabilities.
After carrying the algebra and simplifying, we have the following:
For the event to happen, there is at most 1 sample item less than 3. So we have:
Then the conditional density is obtained by differentiating 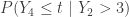 .
.
The following gives the conditional mean  .
.
To contrast, the following gives the information on the unconditional distribution of .
The unconditional mean of is about 3.33. With the additional information that , the average of is now 4.2. So a higher value of pulls up the mean of .
________________________________________________________________________
Practice problems
Practice problems to reinforce the calculation are found in the problem blog, a companion blog to this blog.
________________________________________________________________________


![\displaystyle P(Y_j \le t)=\sum \limits_{k=j}^n \binom{n}{k} \ \biggl[ F(t) \biggr]^k \ \biggl[1-F(x) \biggr]^{n-k} \ \ \ \ \ \ \ \ \ \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+P%28Y_j+%5Cle+t%29%3D%5Csum+%5Climits_%7Bk%3Dj%7D%5En+%5Cbinom%7Bn%7D%7Bk%7D+%5C+%5Cbiggl%5B+F%28t%29+%5Cbiggr%5D%5Ek+%5C+%5Cbiggl%5B1-F%28x%29+%5Cbiggr%5D%5E%7Bn-k%7D+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%281%29&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle P(Y_j > t)=\sum \limits_{k=0}^{j-1} \binom{n}{k} \ \biggl[ F(t) \biggr]^k \ \biggl[1-F(x) \biggr]^{n-k} \ \ \ \ \ \ \ \ \ \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+P%28Y_j+%3E+t%29%3D%5Csum+%5Climits_%7Bk%3D0%7D%5E%7Bj-1%7D+%5Cbinom%7Bn%7D%7Bk%7D+%5C+%5Cbiggl%5B+F%28t%29+%5Cbiggr%5D%5Ek+%5C+%5Cbiggl%5B1-F%28x%29+%5Cbiggr%5D%5E%7Bn-k%7D+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%282%29&bg=ffffff&fg=333333&s=0&c=20201002)
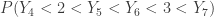

![\displaystyle \begin{aligned} P(Y_4<2<Y_5<Y_6<3<Y_7)&=\frac{10!}{4! \ 2! \ 4!} \biggl[\frac{2}{4} \biggr]^4 \ \biggl[\frac{1}{4} \biggr]^2 \ \biggl[\frac{1}{4} \biggr]^4 \\&\text{ } \\&=\frac{50400}{1048567} \\&\text{ } \\&=0.0481 \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+P%28Y_4%3C2%3CY_5%3CY_6%3C3%3CY_7%29%26%3D%5Cfrac%7B10%21%7D%7B4%21+%5C+2%21+%5C+4%21%7D+%5Cbiggl%5B%5Cfrac%7B2%7D%7B4%7D+%5Cbiggr%5D%5E4+%5C+%5Cbiggl%5B%5Cfrac%7B1%7D%7B4%7D+%5Cbiggr%5D%5E2+%5C+%5Cbiggl%5B%5Cfrac%7B1%7D%7B4%7D+%5Cbiggr%5D%5E4+%5C%5C%26%5Ctext%7B+%7D+%5C%5C%26%3D%5Cfrac%7B50400%7D%7B1048567%7D+%5C%5C%26%5Ctext%7B+%7D+%5C%5C%26%3D0.0481++%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle \begin{aligned} P(Y_4<2<Y_6<3<Y_7)&=\frac{10!}{4! \ 2! \ 4!} \biggl[\frac{2}{4} \biggr]^4 \ \biggl[\frac{1}{4} \biggr]^2 \ \biggl[\frac{1}{4} \biggr]^4 \\& \ \ \ \ + \frac{10!}{5! \ 1! \ 4!} \biggl[\frac{2}{4} \biggr]^5 \ \biggl[\frac{1}{4} \biggr]^1 \ \biggl[\frac{1}{4} \biggr]^4 \\&\text{ } \\&=\frac{50400+40320}{1048567} \\&\text{ } \\&=\frac{90720}{1048567} \\&\text{ } \\&=0.0865 \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+P%28Y_4%3C2%3CY_6%3C3%3CY_7%29%26%3D%5Cfrac%7B10%21%7D%7B4%21+%5C+2%21+%5C+4%21%7D+%5Cbiggl%5B%5Cfrac%7B2%7D%7B4%7D+%5Cbiggr%5D%5E4+%5C+%5Cbiggl%5B%5Cfrac%7B1%7D%7B4%7D+%5Cbiggr%5D%5E2+%5C+%5Cbiggl%5B%5Cfrac%7B1%7D%7B4%7D+%5Cbiggr%5D%5E4+%5C%5C%26+%5C+%5C+%5C+%5C+%2B+%5Cfrac%7B10%21%7D%7B5%21+%5C+1%21+%5C+4%21%7D+%5Cbiggl%5B%5Cfrac%7B2%7D%7B4%7D+%5Cbiggr%5D%5E5+%5C+%5Cbiggl%5B%5Cfrac%7B1%7D%7B4%7D+%5Cbiggr%5D%5E1+%5C+%5Cbiggl%5B%5Cfrac%7B1%7D%7B4%7D+%5Cbiggr%5D%5E4+%5C%5C%26%5Ctext%7B+%7D+%5C%5C%26%3D%5Cfrac%7B50400%2B40320%7D%7B1048567%7D+%5C%5C%26%5Ctext%7B+%7D+%5C%5C%26%3D%5Cfrac%7B90720%7D%7B1048567%7D+%5C%5C%26%5Ctext%7B+%7D+%5C%5C%26%3D0.0865++%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle \begin{aligned} \frac{6!}{a! \ b! \ c!} \ \biggl[\frac{1}{4} \biggr]^a \ \biggl[\frac{2}{4} \biggr]^b \ \biggl[\frac{1}{4} \biggr]^c&=\frac{6!}{0! \ 4! \ 2!} \ \biggl[\frac{1}{4} \biggr]^0 \ \biggl[\frac{2}{4} \biggr]^4 \ \biggl[\frac{1}{4} \biggr]^2=\frac{240}{4096} \\&\text{ } \\&=\frac{6!}{0! \ 5! \ 1!} \ \biggl[\frac{1}{4} \biggr]^0 \ \biggl[\frac{2}{4} \biggr]^5 \ \biggl[\frac{1}{4} \biggr]^1=\frac{192}{4096} \\&\text{ } \\&=\frac{6!}{0! \ 6! \ 0!} \ \biggl[\frac{1}{4} \biggr]^0 \ \biggl[\frac{2}{4} \biggr]^6 \ \biggl[\frac{1}{4} \biggr]^0=\frac{64}{4096} \\&\text{ } \\&=\frac{6!}{1! \ 3! \ 2!} \ \biggl[\frac{1}{4} \biggr]^1 \ \biggl[\frac{2}{4} \biggr]^3 \ \biggl[\frac{1}{4} \biggr]^2=\frac{480}{4096} \\&\text{ } \\&=\frac{6!}{1! \ 4! \ 1!} \ \biggl[\frac{1}{4} \biggr]^1 \ \biggl[\frac{2}{4} \biggr]^4 \ \biggl[\frac{1}{4} \biggr]^1=\frac{480}{4096} \\&\text{ } \\&=\frac{6!}{1! \ 5! \ 0!} \ \biggl[\frac{1}{4} \biggr]^1 \ \biggl[\frac{2}{4} \biggr]^5 \ \biggl[\frac{1}{4} \biggr]^0=\frac{192}{4096} \\&\text{ } \\&=\text{sum of probabilities }=\frac{1648}{4096}=0.4023\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Cfrac%7B6%21%7D%7Ba%21+%5C+b%21+%5C+c%21%7D+%5C+%5Cbiggl%5B%5Cfrac%7B1%7D%7B4%7D+%5Cbiggr%5D%5Ea+%5C+%5Cbiggl%5B%5Cfrac%7B2%7D%7B4%7D+%5Cbiggr%5D%5Eb+%5C+%5Cbiggl%5B%5Cfrac%7B1%7D%7B4%7D+%5Cbiggr%5D%5Ec%26%3D%5Cfrac%7B6%21%7D%7B0%21+%5C+4%21+%5C+2%21%7D+%5C+%5Cbiggl%5B%5Cfrac%7B1%7D%7B4%7D+%5Cbiggr%5D%5E0+%5C+%5Cbiggl%5B%5Cfrac%7B2%7D%7B4%7D+%5Cbiggr%5D%5E4+%5C+%5Cbiggl%5B%5Cfrac%7B1%7D%7B4%7D+%5Cbiggr%5D%5E2%3D%5Cfrac%7B240%7D%7B4096%7D+%5C%5C%26%5Ctext%7B+%7D+%5C%5C%26%3D%5Cfrac%7B6%21%7D%7B0%21+%5C+5%21+%5C+1%21%7D+%5C+%5Cbiggl%5B%5Cfrac%7B1%7D%7B4%7D+%5Cbiggr%5D%5E0+%5C+%5Cbiggl%5B%5Cfrac%7B2%7D%7B4%7D+%5Cbiggr%5D%5E5+%5C+%5Cbiggl%5B%5Cfrac%7B1%7D%7B4%7D+%5Cbiggr%5D%5E1%3D%5Cfrac%7B192%7D%7B4096%7D+%5C%5C%26%5Ctext%7B+%7D+%5C%5C%26%3D%5Cfrac%7B6%21%7D%7B0%21+%5C+6%21+%5C+0%21%7D+%5C+%5Cbiggl%5B%5Cfrac%7B1%7D%7B4%7D+%5Cbiggr%5D%5E0+%5C+%5Cbiggl%5B%5Cfrac%7B2%7D%7B4%7D+%5Cbiggr%5D%5E6+%5C+%5Cbiggl%5B%5Cfrac%7B1%7D%7B4%7D+%5Cbiggr%5D%5E0%3D%5Cfrac%7B64%7D%7B4096%7D+%5C%5C%26%5Ctext%7B+%7D+%5C%5C%26%3D%5Cfrac%7B6%21%7D%7B1%21+%5C+3%21+%5C+2%21%7D+%5C+%5Cbiggl%5B%5Cfrac%7B1%7D%7B4%7D+%5Cbiggr%5D%5E1+%5C+%5Cbiggl%5B%5Cfrac%7B2%7D%7B4%7D+%5Cbiggr%5D%5E3+%5C+%5Cbiggl%5B%5Cfrac%7B1%7D%7B4%7D+%5Cbiggr%5D%5E2%3D%5Cfrac%7B480%7D%7B4096%7D+%5C%5C%26%5Ctext%7B+%7D+%5C%5C%26%3D%5Cfrac%7B6%21%7D%7B1%21+%5C+4%21+%5C+1%21%7D+%5C+%5Cbiggl%5B%5Cfrac%7B1%7D%7B4%7D+%5Cbiggr%5D%5E1+%5C+%5Cbiggl%5B%5Cfrac%7B2%7D%7B4%7D+%5Cbiggr%5D%5E4+%5C+%5Cbiggl%5B%5Cfrac%7B1%7D%7B4%7D+%5Cbiggr%5D%5E1%3D%5Cfrac%7B480%7D%7B4096%7D+%5C%5C%26%5Ctext%7B+%7D+%5C%5C%26%3D%5Cfrac%7B6%21%7D%7B1%21+%5C+5%21+%5C+0%21%7D+%5C+%5Cbiggl%5B%5Cfrac%7B1%7D%7B4%7D+%5Cbiggr%5D%5E1+%5C+%5Cbiggl%5B%5Cfrac%7B2%7D%7B4%7D+%5Cbiggr%5D%5E5+%5C+%5Cbiggl%5B%5Cfrac%7B1%7D%7B4%7D+%5Cbiggr%5D%5E0%3D%5Cfrac%7B192%7D%7B4096%7D+%5C%5C%26%5Ctext%7B+%7D+%5C%5C%26%3D%5Ctext%7Bsum+of+probabilities+%7D%3D%5Cfrac%7B1648%7D%7B4096%7D%3D0.4023%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)

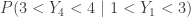
![\displaystyle [0, 1, 3, 3] \ \ \ \ \ \ \frac{280}{78125}=\frac{7!}{0! \ 1! \ 3! \ 3!} \ \biggl[\frac{1}{5} \biggr]^0 \ \biggl[\frac{2}{5} \biggr]^1 \ \biggl[\frac{1}{5} \biggr]^3 \ \biggl[\frac{1}{5} \biggr]^3](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5B0%2C+1%2C+3%2C+3%5D+%5C+%5C+%5C+%5C+%5C+%5C+%5Cfrac%7B280%7D%7B78125%7D%3D%5Cfrac%7B7%21%7D%7B0%21+%5C+1%21+%5C+3%21+%5C+3%21%7D+%5C+%5Cbiggl%5B%5Cfrac%7B1%7D%7B5%7D+%5Cbiggr%5D%5E0+%5C+%5Cbiggl%5B%5Cfrac%7B2%7D%7B5%7D+%5Cbiggr%5D%5E1+%5C+%5Cbiggl%5B%5Cfrac%7B1%7D%7B5%7D+%5Cbiggr%5D%5E3+%5C+%5Cbiggl%5B%5Cfrac%7B1%7D%7B5%7D+%5Cbiggr%5D%5E3&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle [0, 1, 4, 2] \ \ \ \ \ \ \frac{210}{78125}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5B0%2C+1%2C+4%2C+2%5D+%5C+%5C+%5C+%5C+%5C+%5C+%5Cfrac%7B210%7D%7B78125%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle [0, 1, 5, 1] \ \ \ \ \ \ \frac{84}{78125}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5B0%2C+1%2C+5%2C+1%5D+%5C+%5C+%5C+%5C+%5C+%5C+%5Cfrac%7B84%7D%7B78125%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle [0, 1, 6, 0] \ \ \ \ \ \ \frac{14}{78125}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5B0%2C+1%2C+6%2C+0%5D+%5C+%5C+%5C+%5C+%5C+%5C+%5Cfrac%7B14%7D%7B78125%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle [0, 2, 2, 3] \ \ \ \ \ \ \frac{840}{78125}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5B0%2C+2%2C+2%2C+3%5D+%5C+%5C+%5C+%5C+%5C+%5C+%5Cfrac%7B840%7D%7B78125%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle [0, 2, 3, 2] \ \ \ \ \ \ \frac{840}{78125}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5B0%2C+2%2C+3%2C+2%5D+%5C+%5C+%5C+%5C+%5C+%5C+%5Cfrac%7B840%7D%7B78125%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle [0, 2, 4, 1] \ \ \ \ \ \ \frac{420}{78125}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5B0%2C+2%2C+4%2C+1%5D+%5C+%5C+%5C+%5C+%5C+%5C+%5Cfrac%7B420%7D%7B78125%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle [0, 2, 5, 0] \ \ \ \ \ \ \frac{84}{78125}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5B0%2C+2%2C+5%2C+0%5D+%5C+%5C+%5C+%5C+%5C+%5C+%5Cfrac%7B84%7D%7B78125%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle [0, 3, 1, 3] \ \ \ \ \ \ \frac{1120}{78125}=\frac{7!}{0! \ 3! \ 1! \ 3!} \ \biggl[\frac{1}{5} \biggr]^0 \ \biggl[\frac{2}{5} \biggr]^3 \ \biggl[\frac{1}{5} \biggr]^1 \ \biggl[\frac{1}{5} \biggr]^3](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5B0%2C+3%2C+1%2C+3%5D+%5C+%5C+%5C+%5C+%5C+%5C+%5Cfrac%7B1120%7D%7B78125%7D%3D%5Cfrac%7B7%21%7D%7B0%21+%5C+3%21+%5C+1%21+%5C+3%21%7D+%5C+%5Cbiggl%5B%5Cfrac%7B1%7D%7B5%7D+%5Cbiggr%5D%5E0+%5C+%5Cbiggl%5B%5Cfrac%7B2%7D%7B5%7D+%5Cbiggr%5D%5E3+%5C+%5Cbiggl%5B%5Cfrac%7B1%7D%7B5%7D+%5Cbiggr%5D%5E1+%5C+%5Cbiggl%5B%5Cfrac%7B1%7D%7B5%7D+%5Cbiggr%5D%5E3&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle [0, 3, 2, 2] \ \ \ \ \ \ \frac{1680}{78125}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5B0%2C+3%2C+2%2C+2%5D+%5C+%5C+%5C+%5C+%5C+%5C+%5Cfrac%7B1680%7D%7B78125%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle [0, 3, 3, 1] \ \ \ \ \ \ \frac{1120}{78125}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5B0%2C+3%2C+3%2C+1%5D+%5C+%5C+%5C+%5C+%5C+%5C+%5Cfrac%7B1120%7D%7B78125%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle [0, 3, 4, 0] \ \ \ \ \ \ \frac{280}{78125}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5B0%2C+3%2C+4%2C+0%5D+%5C+%5C+%5C+%5C+%5C+%5C+%5Cfrac%7B280%7D%7B78125%7D&bg=ffffff&fg=333333&s=0&c=20201002)

![\displaystyle \begin{aligned} P(1<Y_1<3)&=P(Y_1<3)-P(Y_1<1) \\&=1-\biggl( \frac{2}{5} \biggr)^7 -\biggl[1-\biggl( \frac{4}{5} \biggr)^7 \biggr] \\&=\frac{77997-61741}{78125} \\&=\frac{16256}{78125} \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+P%281%3CY_1%3C3%29%26%3DP%28Y_1%3C3%29-P%28Y_1%3C1%29+%5C%5C%26%3D1-%5Cbiggl%28+%5Cfrac%7B2%7D%7B5%7D+%5Cbiggr%29%5E7+-%5Cbiggl%5B1-%5Cbiggl%28+%5Cfrac%7B4%7D%7B5%7D+%5Cbiggr%29%5E7+%5Cbiggr%5D+%5C%5C%26%3D%5Cfrac%7B77997-61741%7D%7B78125%7D+%5C%5C%26%3D%5Cfrac%7B16256%7D%7B78125%7D+%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)


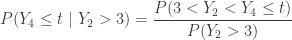
![\displaystyle [0, 4, 1] \ \ \ \ \ \ \frac{5!}{0! \ 4! \ 1!} \ \biggl[\frac{3}{5} \biggr]^0 \ \biggl[\frac{t-3}{5} \biggr]^4 \ \biggl[\frac{5-t}{5} \biggr]^1](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5B0%2C+4%2C+1%5D+%5C+%5C+%5C+%5C+%5C+%5C+%5Cfrac%7B5%21%7D%7B0%21+%5C+4%21+%5C+1%21%7D+%5C+%5Cbiggl%5B%5Cfrac%7B3%7D%7B5%7D+%5Cbiggr%5D%5E0+%5C+%5Cbiggl%5B%5Cfrac%7Bt-3%7D%7B5%7D+%5Cbiggr%5D%5E4+%5C+%5Cbiggl%5B%5Cfrac%7B5-t%7D%7B5%7D+%5Cbiggr%5D%5E1&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle [0, 5, 0] \ \ \ \ \ \ \frac{5!}{0! \ 5! \ 0!} \ \biggl[\frac{3}{5} \biggr]^0 \ \biggl[\frac{t-3}{5} \biggr]^5 \ \biggl[\frac{5-t}{5} \biggr]^0](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5B0%2C+5%2C+0%5D+%5C+%5C+%5C+%5C+%5C+%5C+%5Cfrac%7B5%21%7D%7B0%21+%5C+5%21+%5C+0%21%7D+%5C+%5Cbiggl%5B%5Cfrac%7B3%7D%7B5%7D+%5Cbiggr%5D%5E0+%5C+%5Cbiggl%5B%5Cfrac%7Bt-3%7D%7B5%7D+%5Cbiggr%5D%5E5+%5C+%5Cbiggl%5B%5Cfrac%7B5-t%7D%7B5%7D+%5Cbiggr%5D%5E0&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle [1, 3, 1] \ \ \ \ \ \ \frac{5!}{1! \ 3! \ 1!} \ \biggl[\frac{3}{5} \biggr]^1 \ \biggl[\frac{t-3}{5} \biggr]^3 \ \biggl[\frac{5-t}{5} \biggr]^1](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5B1%2C+3%2C+1%5D+%5C+%5C+%5C+%5C+%5C+%5C+%5Cfrac%7B5%21%7D%7B1%21+%5C+3%21+%5C+1%21%7D+%5C+%5Cbiggl%5B%5Cfrac%7B3%7D%7B5%7D+%5Cbiggr%5D%5E1+%5C+%5Cbiggl%5B%5Cfrac%7Bt-3%7D%7B5%7D+%5Cbiggr%5D%5E3+%5C+%5Cbiggl%5B%5Cfrac%7B5-t%7D%7B5%7D+%5Cbiggr%5D%5E1&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle [1, 4, 0] \ \ \ \ \ \ \frac{5!}{1! \ 4! \ 0!} \ \biggl[\frac{3}{5} \biggr]^1 \ \biggl[\frac{t-3}{5} \biggr]^4 \ \biggl[\frac{5-t}{5} \biggr]^0](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5B1%2C+4%2C+0%5D+%5C+%5C+%5C+%5C+%5C+%5C+%5Cfrac%7B5%21%7D%7B1%21+%5C+4%21+%5C+0%21%7D+%5C+%5Cbiggl%5B%5Cfrac%7B3%7D%7B5%7D+%5Cbiggr%5D%5E1+%5C+%5Cbiggl%5B%5Cfrac%7Bt-3%7D%7B5%7D+%5Cbiggr%5D%5E4+%5C+%5Cbiggl%5B%5Cfrac%7B5-t%7D%7B5%7D+%5Cbiggr%5D%5E0&bg=ffffff&fg=333333&s=0&c=20201002)

![\displaystyle P(Y_2 >3)=\binom{5}{0} \ \biggl[\frac{3}{5} \biggr]^0 \ \biggl[\frac{2}{5} \biggr]^5 +\binom{5}{1} \ \biggl[\frac{3}{5} \biggr]^1 \ \biggl[\frac{2}{5} \biggr]^4=\frac{272}{3125}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+P%28Y_2+%3E3%29%3D%5Cbinom%7B5%7D%7B0%7D+%5C+%5Cbiggl%5B%5Cfrac%7B3%7D%7B5%7D+%5Cbiggr%5D%5E0+%5C+%5Cbiggl%5B%5Cfrac%7B2%7D%7B5%7D+%5Cbiggr%5D%5E5+%2B%5Cbinom%7B5%7D%7B1%7D+%5C+%5Cbiggl%5B%5Cfrac%7B3%7D%7B5%7D+%5Cbiggr%5D%5E1+%5C+%5Cbiggl%5B%5Cfrac%7B2%7D%7B5%7D+%5Cbiggr%5D%5E4%3D%5Cfrac%7B272%7D%7B3125%7D&bg=ffffff&fg=333333&s=0&c=20201002)



![\displaystyle f_{Y_4}(t)=\frac{5!}{3! \ 1! \ 1!} \ \biggl[\frac{t}{5} \biggr]^3 \ \biggl[\frac{1}{5} \biggr] \ \biggl[ \frac{5-t}{5} \biggr]^1=\frac{20}{3125} \ (5t^3-t^4)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+f_%7BY_4%7D%28t%29%3D%5Cfrac%7B5%21%7D%7B3%21+%5C+1%21+%5C+1%21%7D+%5C+%5Cbiggl%5B%5Cfrac%7Bt%7D%7B5%7D+%5Cbiggr%5D%5E3+%5C+%5Cbiggl%5B%5Cfrac%7B1%7D%7B5%7D+%5Cbiggr%5D+%5C+%5Cbiggl%5B+%5Cfrac%7B5-t%7D%7B5%7D+%5Cbiggr%5D%5E1%3D%5Cfrac%7B20%7D%7B3125%7D+%5C+%285t%5E3-t%5E4%29&bg=ffffff&fg=333333&s=0&c=20201002)
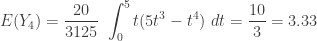


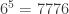 different outcomes. How many of these outcomes have three scores appearing in such a way that one score appears three times, and each of the other two scores appears once?
different outcomes. How many of these outcomes have three scores appearing in such a way that one score appears three times, and each of the other two scores appears once?

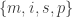 . Draw 11 letters at random from this population with replacement. The total number of 11-character letter strings that can be formed is
. Draw 11 letters at random from this population with replacement. The total number of 11-character letter strings that can be formed is 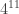 . How many of these character strings contain one m, four i’s, four s’s and two p’s?
. How many of these character strings contain one m, four i’s, four s’s and two p’s? and
and  are positive integers such that
are positive integers such that 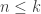 . Suppose we have nonnegative integers
. Suppose we have nonnegative integers  such that
such that 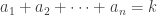 . The following is the number of ways to partition a set of
. The following is the number of ways to partition a set of  objects, the second subgroup consists of
objects, the second subgroup consists of 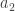 objects and so on.
objects and so on.
 is the result of a combinatoric observation below. The result
is the result of a combinatoric observation below. The result 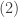 is the multinomial theorem.
is the multinomial theorem.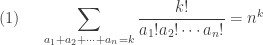
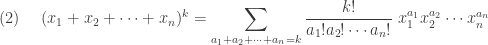
 many ordered samples. The following two strings are two examples:
many ordered samples. The following two strings are two examples:
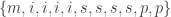 . A more compact way of notating this unordered sample is
. A more compact way of notating this unordered sample is 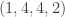 , where the first coordinate is the number of m’s, the second coordinate is the number of i’s, the third coordinate is the number of s’s, and the fourth coordinate is the number of p’s. Note that the sum of the four is 11. The number of ordered samples that are tied to
, where the first coordinate is the number of m’s, the second coordinate is the number of i’s, the third coordinate is the number of s’s, and the fourth coordinate is the number of p’s. Note that the sum of the four is 11. The number of ordered samples that are tied to 
 many unordered samples. Furthermore, the equation
many unordered samples. Furthermore, the equation  has 364 many nonnegative integer solutions.
has 364 many nonnegative integer solutions. many ways of doing this. Furthermore, the equation
many ways of doing this. Furthermore, the equation  with replacement. There are
with replacement. There are 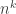 many ordered samples. These ordered samples can be collapsed into
many ordered samples. These ordered samples can be collapsed into 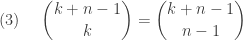
 is obtained by
is obtained by 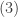 .
. is:
is:
 in the polynomial expansion can be considered as an unordered sample in the finite sampling with replacement. Thus both results of
in the polynomial expansion can be considered as an unordered sample in the finite sampling with replacement. Thus both results of 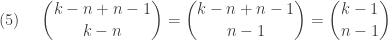
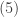 provides the number of positive integer solutions to the equation
provides the number of positive integer solutions to the equation  . Suppose that in each trial, the probability of the outcome
. Suppose that in each trial, the probability of the outcome 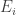 is
is  . Furthermore, we have
. Furthermore, we have 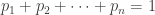 .
. , i.e. an ordered sample when sampling
, i.e. an ordered sample when sampling 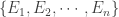 with replacement. Consider the ordered samples where the outcome
with replacement. Consider the ordered samples where the outcome  occurs
occurs 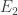 occurs
occurs 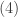 above is the number of all such ordered samples. Thus the following is the probability that in
above is the number of all such ordered samples. Thus the following is the probability that in 
 , let
, let 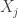 be the number of times the event
be the number of times the event  occurs in the
occurs in the  .
. 
 . Furthermore we have:
. Furthermore we have:
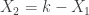 . As a result,
. As a result,  has a univariate distribution, which is the binomial distribution.
has a univariate distribution, which is the binomial distribution.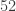 cards, five fair dice are rolled. The resulting five scores from the dice form a poker dice hand. The possible hands are ranked as follows:
cards, five fair dice are rolled. The resulting five scores from the dice form a poker dice hand. The possible hands are ranked as follows: ).
). ).
).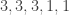 ).
). ).
).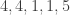 ).
). ).
).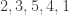 ).
).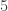 dice, there are
dice, there are  indicates outcome that the first die results in a two and the second die results in a three and so on (this is a three of a kind). To find the probability of a three of a kind, we simply divide the number of ways such hands can occur by
indicates outcome that the first die results in a two and the second die results in a three and so on (this is a three of a kind). To find the probability of a three of a kind, we simply divide the number of ways such hands can occur by  . We use the multinomial coefficients to obtain the number of outcomes for each type of poker dice hands.
. We use the multinomial coefficients to obtain the number of outcomes for each type of poker dice hands.  cells. As will be shown below, the problem of computing the probabilities of poker dice hands is seen through the lens of the occupancy problem of randonly placing
cells. As will be shown below, the problem of computing the probabilities of poker dice hands is seen through the lens of the occupancy problem of randonly placing  denotes a three of a kind hand of
denotes a three of a kind hand of 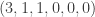 is also a three of a kind hand, representing the outcome that the score of one appearing three times, the score of two appearing one time and the score of three appearing one time. We use the multinomial coefficients to determine how many of the
is also a three of a kind hand, representing the outcome that the score of one appearing three times, the score of two appearing one time and the score of three appearing one time. We use the multinomial coefficients to determine how many of the 
 , four
, four  , four
, four  and two
and two  , there are
, there are  possible
possible  -letter strings that can be formed, of which
-letter strings that can be formed, of which 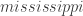 is one specific example.
is one specific example.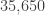 .
.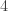 two times, a
two times, a  one time, a
one time, a  . We are trying to partition
. We are trying to partition 
 possible hands,
possible hands, 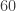 of them satisfiy the condition that a
of them satisfiy the condition that a 
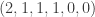 are examples of one pair. In essense, we need to count all the occupancy number sets such that among the
are examples of one pair. In essense, we need to count all the occupancy number sets such that among the  and three of the cells are
and three of the cells are  . To this end, we apply the multinomial theorem twice, one time on the five rolls of dice and one time one the
. To this end, we apply the multinomial theorem twice, one time on the five rolls of dice and one time one the 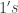 and one with two
and one with two  . The following is the multinomial coefficient (the second application of the multinomial theorem):
. The following is the multinomial coefficient (the second application of the multinomial theorem):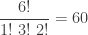
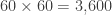 and for a random poker dice hand, the probability that it is a one pair is:
and for a random poker dice hand, the probability that it is a one pair is:

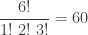
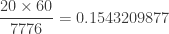







 (Revised March 28, 2015)
(Revised March 28, 2015) with
with 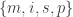 . Suppose we sample
. Suppose we sample 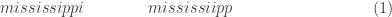
 ,
, 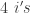 ,
,  and
and  . We represent the unordered sample in two ways:
. We represent the unordered sample in two ways: , the number of
, the number of 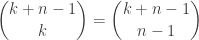 many unordered samples, either represented as
many unordered samples, either represented as  bars and
bars and  calculated above. This is also the total number of non-negative integer solutions to the equation
calculated above. This is also the total number of non-negative integer solutions to the equation 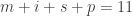 . Thinking of an unordered sample as a
. Thinking of an unordered sample as a  . Suppose that each letter is already selected once. Then we need to sample
. Suppose that each letter is already selected once. Then we need to sample 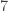 more times out of these
more times out of these  . To generalize, if the population size is
. To generalize, if the population size is 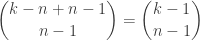 many unordered samples in which all objects in the population are represented in each sample.
many unordered samples in which all objects in the population are represented in each sample.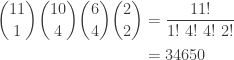
 in the remaining
in the remaining 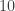 positions and so on.
positions and so on. where
where 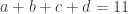 , the total number of ordered samples equivalent to this unordered sample is
, the total number of ordered samples equivalent to this unordered sample is  . As we shall see, these are called multinomial coefficients.
. As we shall see, these are called multinomial coefficients.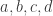 are non-negative integers:
are non-negative integers:
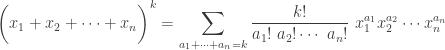
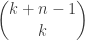 , which is the number of non-negative integer solutions to the equation
, which is the number of non-negative integer solutions to the equation 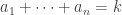 . Each term
. Each term 
 ) and we have
) and we have  ,
,  and so on, then the multinomial coefficient in
and so on, then the multinomial coefficient in  . We have
. We have 
